
NEO4J
Graphs are everywhere.
Loading your data to Neo4j shouldn't be hard.
What Is Neo4j?
Neo4j is the world's leading graph database management system, designed for optimized fast management, storage, and traversal of nodes and relationships.
Neo4j is a highly scalable, native, and open-source graph database, built to leverage data, especially the relationships between and within data. It delivers constant real-time performance, which enables enterprises to build applications to meet today’s evolving data challenges.
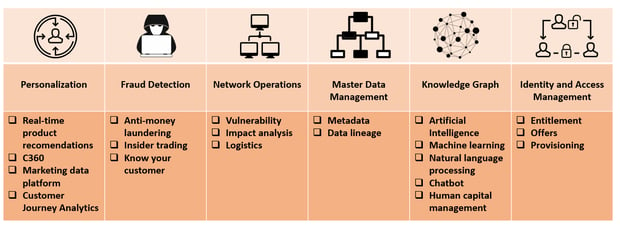
Graphs are everywhere. All data is linked, any use case where you want to investigate how data is connected rather than look at individual data points is a potential graph use case.
The Neo4j graph algorithms for fraud detection, recommendations, etc allow organizations to analyze their data in ways that simply were not possible before.

Use cases
Having nodes with their relationships stored together in the database opens a number of use cases, without having to recalculate the relationships (or joins) for every single query, opens up a whole series of new use cases that would be very hard or impossible to implement with relational databases.
Although mathematical graph theories have been around for centuries, it took until recently for graph databases to become popular. Increased access to cheap and powerful computing resources and the development of mainly graph database market leader Neo4j have created a huge increase in demand for graph databases

Your graph database needs data before you can start exploring relationships. Loading data is not a trivial task, especially if you need a reliable, repeatable and performant data loading process.
Apache Hop is unparalleled in its support for Neo4j. Hop comes with over 20 Neo4j-specific plugins to load data to and from Neo4, to build or split graph models, even to log your workflow and pipelines execution to a graph.
Hop's visually developed workflows and pipelines and project life cycle management make it the perfect fit to reliably load data to and from your Neo4j graphs.
Scalability
Currently, a large Neo4j graph database may have trillions of nodes. Suppose that your application suddenly becomes incredibly popular. Consider that the traffic and the volume of data is growing fast, and your database gets more overloaded every day.
Imagine your business entities and relations as a single graph. The physical storage of such a graph is divided, or sharded, across many servers or clusters, despite the fact that it’s still a single graph dataset.
Although common in the world of relational databases, sharding is pretty new to graphics databases.

What is sharding?
Sharding is a method of splitting and storing a single logical dataset in multiple databases. By distributing the data among multiple machines, a cluster of database systems can store larger dataset and handle additional requests.
Sharding is necessary if a dataset is too large to be stored in a single database. Moreover, many sharding strategies allow additional machines to be added. Sharding allows a database cluster to scale along with its data and traffic growth.
Federated graphs
In general terms, a federated database is a type of database management system that maps multiple autonomous database systems into one federated database. A federated graph places several sharded graphs cooperatively. Consequently, all those graphs can be queried as a single big graph database.
Why use a federated graph? Because a graph will ensure you can ask any question you want and to perform graph analytics at scale. While sharding divides graphs, federated graphs bring multiple graphs together, supporting queries across graph databases that may have different logical structures.
And since “Graphs are everywhere”, there are graphs across every organization. Suppose that you have a graph for each business process (goal, department). In this case, a federated graph will allow you to run queries through all of your graphs.
Security
Intelligence applications appear with new requirements and demand better performance. As a result, today's databases must keep up with these changes and adhere to rigorous business security rules. At the same time, the practices are required to remain simple to implement and manage.
Neo4j offers identity and access control using Kerberos and LDAP. Communications with the database take place over Neo4j’s internal binary protocol or using HTTPS requests.

Neo4j Schema-Based Security
In addition to standard enterprise security features, Neo4j started schema-based security. But, how does schema-based security work?
Schema-based security:
• Restricts what data can be seen by different users (role-based access)
• Uses database and schema information to define restrictions
• Applies these restrictions to all database interactions
Schema-based security represents a significant advance in graph database security.
Flexibility
Intelligent applications appear with new requirements and demand better performance.
Today's agile and test-driven development practices demand that applications evolve with changing business requirements.
Modern graph databases like Neo4j are prepared for frictionless development and best practices.

Today many relational database applications are stable and functional within their own limitations.
However, others show some clear indications of stress, mainly induced by the database. Note that a relational database management system is sometimes used to handle highly connected data.
Performance
If you are looking for a graph database solution Neo4j is the way to go. It is the easiest and most robust solution to use on the market.
Even so, the community version is free and the community support around Neo4j is really good. The database performance is extremely fast.
The Neo4j native graph database delivers consistent, real-time performance for multi-hop queries on large, interconnected datasets.
Query optimization
Indexes and constraints can be added when desired, in order to gain performance and modeling benefits.
A graph database implements traversals and that’s precisely the reason for using indexes in a graph database. The goal is to find the started point of a graph traversal.
Once that point is found, the traversal is based on a graph structure to achieve high performance.
If you are doing data science, you can try the Neo4j Graph Data Science library for high-performance graph analytics algorithms.
High Availability
It’s possible to keep the lights on in a 24×7 production environment using Neo4j High Availability (HA).
Neo4j’s High Availability solution provides replication across a cluster of machines, for maximum read scaling and reliable uptime.

Cluster
Neo4j’s High Availability enables a torrent of data flowing to clients by replicating the graph across a synchronized cluster of servers.
The logical cluster can operate within a single data center, or be spread out across the globe, without sacrificing performance or security.
Developer Friendly
Neo4j minimizes learning-related downtime, thanks to a mature UI with intuitive interaction and built-in learning. You’ll also have access to a wealth of learning materials, thanks to the Neo4j community
You want a solution that minimizes downtime, especially when you’re running mission-critical applications. Using Neo4j, you engage with graph experts who provide world-class support for your organization without compromising on scalability, performance, or security.

Easy-to-Use
Select from APIs and drivers for all major languages, including Cypher, the world’s most powerful and productive graph query language, or the native Java API for writing custom extensions.
The logical model is the physical model, and with Neo4j, you’re empowered to make reflective of the ever-changing business landscape. Flexibility and rapid response are the name of the game.
Worried about importing massive amounts of data? Loading data is rapid and simple, with a staggering loading speed for even huge data sets, all with very low memory footprint.