Automate everything!
Analytics projects are often treated as ad-hoc projects. Code and content are...

Amazon SageMaker is a "fully managed machine learning service". This means it provisions an environment for data scientists and developers without them needing to worry about managing servers.
Please note: at the time of this post Amazon SageMaker is only available in the Ireland region for Europe.Leveraging the ease-of-use of Jupyter Notebooks, SageMaker enables you to easily explore and analyze data, sadly the service does not (yet) support JupyterLab.
Training and hosting instances are billed by seconds of usage, with notebook instances being billed hourly.
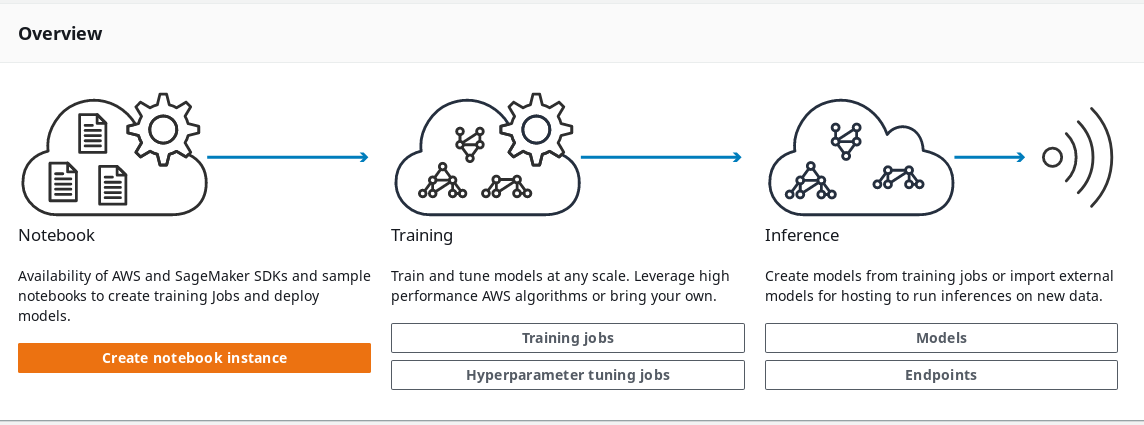
When we first visit the Amazon SageMaker dashboard we are asked to create a notebook instance. Here we can choose a name, an instance type, an IAM role, a VPC, configure the instance's life cycle and choose an encryption key for the notebook data.
This indicates how Amazon has built a product that works on top of their own services. Next to Jupyter instances the service is enriched by the SageMaker (open source) libraries Python and Spark.
In fact, SageMaker actually gives a very transparent vibe and allows you to use Amazon's or your own algorithms and frameworks. Furthermore the service hosts jobs, models and endpoints.
Taking a more detailed look, this is all done by using the benefits of Docker (ECS) and S3 to create an environment many teams would strive for. Ready for you to use right out of the box!
Amazon's algorithms are well-documented and they've provided numerous example notebooks for you to explore. These are also available on any newly created Notebook server.
An overview of the Amazon SageMaker workflow
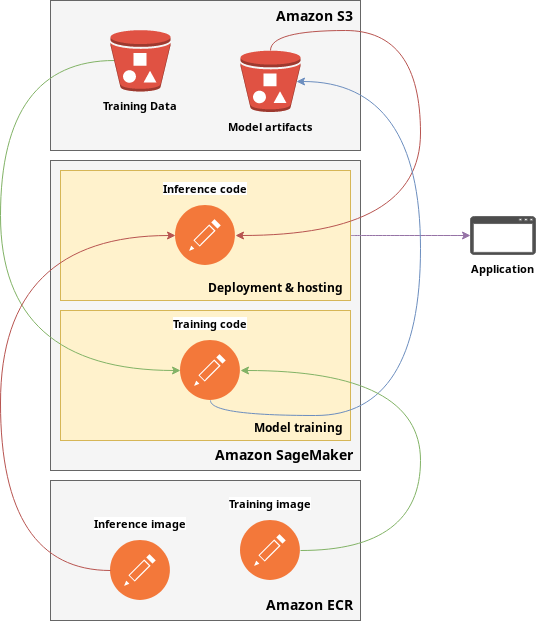
The above image shows a simplified workflow on SageMaker.
After some data wrangling we train a model using a training image stored on Amazon ECR (green). We then have model artifacts (blue) which we can use to run, test and deploy (red). An endpoint is created to give applications access to the trained model and run inferences on new data (purple).
A few noteworthy realizations

Amazon SageMaker streamlines the creation of ML pipelines and minimizes the need for maintenance while simultaneously cutting costs as you only pay for what you use. It comes with various (open-source) features and enables you to run "bring your own"-code.
Be sure to keep an eye on our blog in the coming weeks as we take a deeper dive into Amazon SageMaker!


Analytics projects are often treated as ad-hoc projects. Code and content are...

ETL development heavily relies on the desktop with...

Cloud computing is the way to the future, and the way to bring your company to the next level. With...
Blog comments