
The Apache Hop community released Apache Hop 2.8.0 late last week. This release contains over three...
Bart Maertens


The Apache Hop community released version 2.7.0 earlier this month. Let's take a closer look at what this release brings.
In addition to some behind-the-scenes cleanup and refactoring, this release contains improvements and new functionality. Well over half of the fixes and new functionalities in this release were contributed by know.bi.
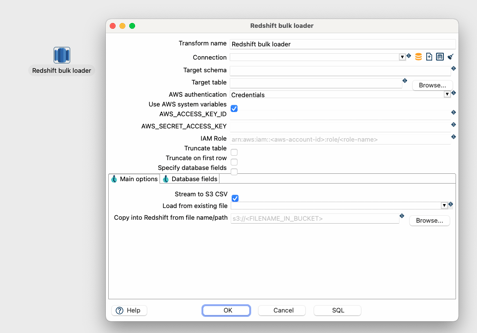
Redshift Bulk Loader
Loading data to cloud databases can be painfully slow. Transferring data in and out of cloud environments (or even within a cloud environment) comes with lots of latency that often prevents quick data loading. The larger data volumes that need to be loaded into analytical databases usually only make matters worse.
A typical solution is to upload data to files in the cloud environment and perform a bulk load from the database directly. Apache Hop already contains bulk loader transforms for row-based relational databases and the Vertica and Snowflake analytical databases. A bulk loader for AWS Redshift was missing.
Apache Hop 2.7.0 brings a new AWS Redshift Bulk Loader transform (contributed by know.bi) that allows lightning-fast data loading to AWS Redshift.
The transform lets you stream data to CSV files in an S3 bucket and then use the Redshift COPY command to bulk-load the data to Redshift. Alternatively, existing S3 files in CSV or Parquet format can be used to copy data into Redshift.
Improved Formula Transform
The Formula transform, introduced in the early 2.x Apache Hop releases, received some major updates and bug fixes in 2.7.0.
The Formula transform, just like the Excel transforms, uses the Apache POI project, and was upgraded to version 5.2.4.
Formulas in Apache Hop pipelines now support inline fields: fields created by earlier formula lines in the same transform can now be used in later formula lines.
Some minor issues in data type and null or empty value handling were added, the overall performance of the transform improved. Additionally, some improvements were made in the way formulas in the old proprietary PDI/Kettle formula format are converted to Apache POI formulas (which are almost 100% Excel compatible).
Various improvements
- the Enhanced JSON Output transform now supports easier creation of arrays
- the PDI/Kettle importer was improved, with better support for the XML Join, Multiway Merge Join, Formula and other transforms.
- JDBC Driver handling was improved. This is a technical change that will go unnoticed for most data engineers. However, if you use the HOP_SHARED_JDBC_FOLDER environment variable, you will need to change that to HOP_SHARED_JDBC_FOLDERS (ending in 'S'). This new variable supports multiple (comma-separated) paths. Check the documentation for more details.
- the Apache Hop translations continue to receive updates, with lots of improvements and new translations in the Brazilian Portuguese (pt_BR) translations. Check the translation contribution guide if you'd like to help translating Apache Hop into your native language.
- transform and action names in Hop Gui are now underlined when you hover over them. This change makes the transform or action names look and behave like hyperlinks, which should make it more intuitive for Apache Hop data engineers to click on a transform name to go straight to that transform or action's properties.

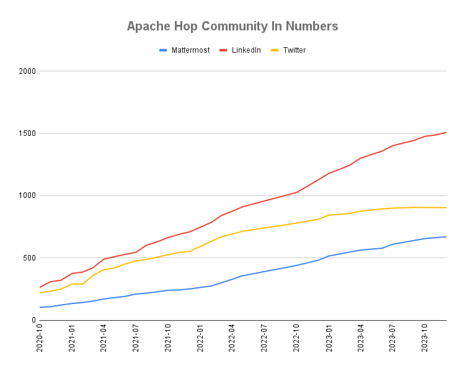
Community Growth
The Apache Hop community continues to grow (even though @ApacheHop lost 2 followers on Twitter X).
Building a growing and thriving community is one of the tasks every incubating project gets when they join the ASF Incubator. Even though Apache Hop graduated as a Top-Level project 2 years ago, building and growing a community remains equally as important as continuously improving the software.
The Apache Hop community is distributed all over the globe, and new members are added continuously.


Blog comments