
The Apache Hop community released Apache Hop 2.8.0 late last week. This release contains over three...
Bart Maertens


The Apache Hop team released Apache Hop 2.3.0 earlier this week.
This release contains almost two months of work on over 80 github issues. Even though most of the issues worked on were bug fixes, this release does contain a number of interesting new features. Let's explore those in more detail.
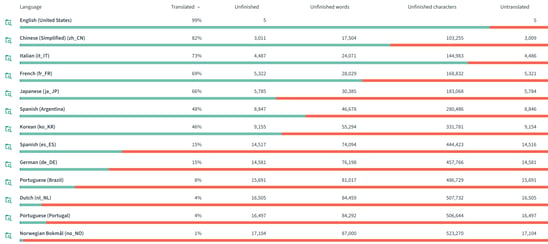
Weblate - Web-based translation tool
The old Hop Translator tool was revived from the PDI/Kettle code at the start of Project Hop, even before the project became Apache Hop. Even though Hop Translator makes translating Apache Hop easier, it doesn't make it really easy for non-developers.
The Apache Hop team decided to call open source to the rescue and added Weblate, a web-based continuous localization platform. Translations are now easier than ever: just create an account and browse to the relevant sections to start translating Apache Hop to your native language. Weblate will assist you in creating pull request to the Apache Hop code base, so you can focus on earning Hop rockstar points.
Documentation
A lot of documentation was added or updated for Apache Hop 2.3.0. A couple of notable changes in the docs are:
- layout changes: commands now have separate tabs for Windows and Linux/MacOS, large help, command and table sections can now be expanded or collapsed for easier navigation.
- the Metadata Injection documentation was rewritten, new samples are available in the Samples project. Metadata Injection is one of the lesser-known powerful features in Apache Hop that allows you to inject metadata (filenames, file layouts, table names etc) into a template pipeline at runtime. Common use cases are onboarding large sets of files with different layouts into your database or data lake, without having to write a pipeline for each file layout.
- extended Pipeline Probe documentation explains how a pipeline's data can be sent to another pipeline for e.g. data data quality checks, profiling etc.
- a list of community blog posts and articles bundles all (known) posts about Apache Hop that could otherwise go unnoticed.
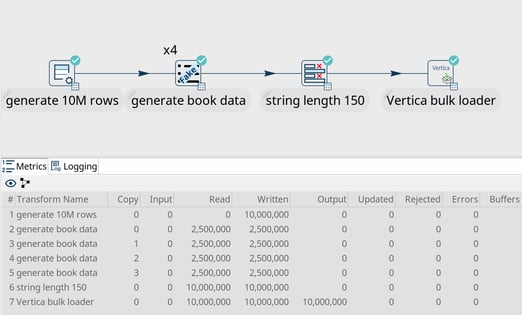
Vertica Bulk Loader transform
Vertica is a lightning-fast distributed analytical database. This new bulk loader transform lets you load high-volume data a lot faster than would be possible with a Table Output transform.
The Samples project contains an example pipeline with instructions on how to run the Vertica bulk loader against a single-node database cluster in Docker. This image uses the Vertica Community Edition (CE). The CE version lets you use 1TB in a cluster of maximum 3 nodes for testing purposes. This single node container will offer plenty of power to test the bulk loader transform.
The Vertica JDBC driver is available for free, but does not use an Apache-compatible license, so you'll need to download the driver and add it to `<hop>/plugins/databases/vertica/lib`.
Once that's done, you'll be able to follow the steps in the sample pipeline (`transforms/vertica-docker.hpl`, the database name to use is `vmart`). The sample pipeline will generate 10 million rows of fake book data to the "books" table you just created. Generating and the data loading this data set shouldn't take much longer than one minute, with loading speeds of up to 200.000 rows per second on a typical laptop. Loading speeds on real systems can/will even go much faster.
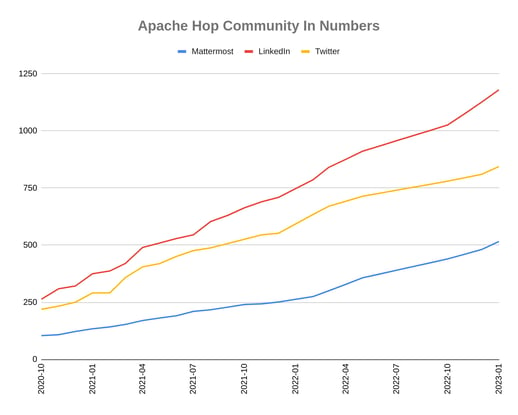
Community
As an Apache project, the community is key for Apache Hop. The Apache Hop community continues to grow in the number of community members, geographical areas, and contributions, even over the relatively slow winter holiday period.
Great communities build great software, a huge thank you and shoutout to everyone who was involved to make Apache Hop 2.3.0 the big release it is.
Apache Hop and know.bi
At know.bi, we were involved with Apache Hop since its inception. We are active and proud community members and contributors and will continue to do so. Get in touch if you'd like to find out more about how know.bi and Apache Hop can help you solve your data engineering and data orchestration challenges.



Blog comments