Bart Maertens

Apache Hop has excellent support for Neo4j, as we've already covered in a number of previous blog posts.
However, Neo4j is not the only graph platform Apache Hop supports. Graphs are everywhere, and each and every graph database that implements the OpenCypher graph query language and bolt protocol works with Apache Hop.
We'll take a look at Memgraph in this post, later posts will cover AWS Neptune, CAPS (Cypher for Apache Spark) and others. Let us know in the comments if there are other OpenCypher graph databases you'd like to see covered.
What is Memgraph
From the Memgraph website: "Memgraph is an open source graph database built for teams who expect highly performant, advanced analytical insights - as compatible with your current infrastructure as Neo4j (but up to 120x faster)."
The Memgraph open source project is developed by a London-based company. With their (Open)Cypher language and Bolt protocol implementations, Memgraph claims to be a drop-in Neo4j alternative. Let's put that bold claim to the test.
Running Memgraph
Memgraph provides a container image that we'll use to get up and running with a single command.
The -e MEMGRAPH="--bolt-server-name-for-init=Neo4j/" environment variable tells Memgraph to connect over the Bolt protocol.
docker run -it -p 7687:7687 -p 7444:7444 -p 3000:3000 -e MEMGRAPH="--bolt-server-name-for-init=Neo4j/" memgraph/memgraph-platform
Once the image is pulled and the memgraph database service has started, you'll be connected to the Memgraph shell:
Status: Downloaded newer image for memgraph/memgraph-platform:latest
Memgraph Lab is running at localhost:3000
mgconsole 1.3
Connected to 'memgraph://127.0.0.1:7687'
Type :help for shell usage
Quit the shell by typing Ctrl-D(eof) or :quit
memgraph>
Connect to the Memgraph Lab console in your browser at http://localhost:3000. A username and password are not required by default.
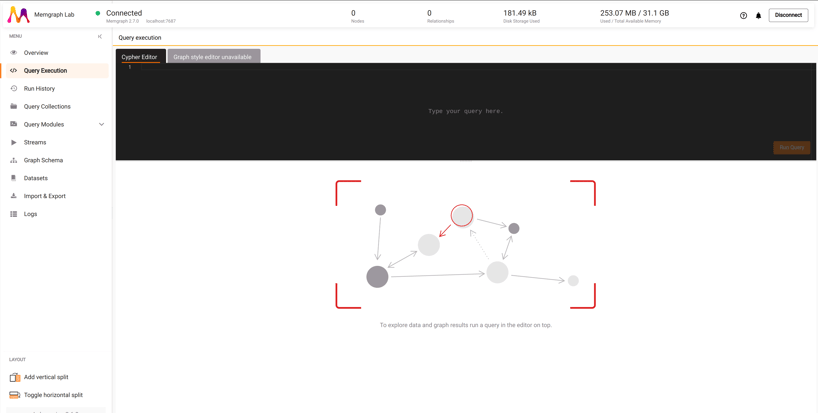
Connection to Memgraph and loading data with Apache Hop
Loading data to Memgraph is almost as easy as running Memgraph. Apache Hop comes with a sample workflow and a set of pipelines that loads Rik Van Bruggen's beer graph (yes, that post is over 10 years old, and still valid).
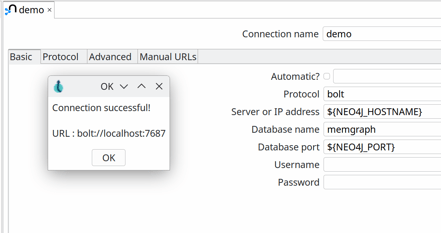
Open your Hop Gui, switch to the metadata perspective and edit the Neo4j demo connection. We only need to make a couple of minor changes to the default settings: you need to disable the automatic option, specify bolt as the protocol and memgraph as the database name. The hostname (localhost) and database port can remain unchanged, with localhost and 7687 as the (parameterized) default settings. Username and password are not required, so you can just clear both fields.
Hit the test button, you should have a working connection to Memgraph.
Now, switch back to the data orchestration perspective and open the 'neo4j/beers-wikipedia-graph.hwf' workflow from the samples project.
This workflow scrapes Wikipedia's Belgian beers list page and loads it to a graph database. This workflow also contains the only plugins known not to work with Memgraph: the Neo4j Index and Neo4j Constraint actions. There is an open ticket to add Memgraph support for these actions. Feel free to reach out or let us know in the comments if you need this implemented quickly.
Since the Beer graph is relatively small, we'll just skip creating indexes and constraints. Remove both actions from the workflow and create a hop from Check Neo4j to Read and scrub the data. You workflow should now look like in the screenshot below.
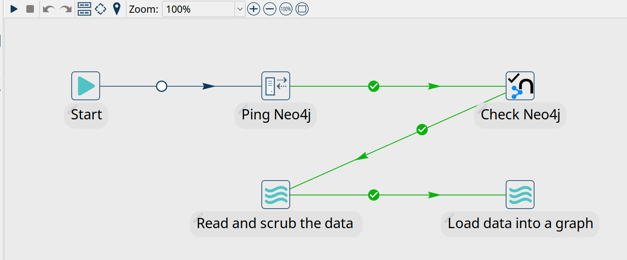
Running this workflow should only take a couple of seconds. Your logging output will be similar to the output shown below.
2023/05/15 10:07:10 - Update Belgian Beers graph.0 - Finished processing (I=0, O=2647, R=2647, W=2647, U=0, E=0)
2023/05/15 10:07:10 - beers-wikipedia-graph-output - Pipeline duration : 6.132 seconds [ 6.131" ]
2023/05/15 10:07:10 - beers-wikipedia-graph-output - Execution finished on a local pipeline engine with run configuration 'local'
2023/05/15 10:07:10 - beers-wikipedia-graph - Finished action [Load data into a graph] (result=[true])
2023/05/15 10:07:10 - beers-wikipedia-graph - Finished action [Read and scrub the data ] (result=[true])
2023/05/15 10:07:10 - beers-wikipedia-graph - Finished action [Check Neo4j] (result=[true])
2023/05/15 10:07:10 - beers-wikipedia-graph - Finished action [Ping Neo4j] (result=[true])
2023/05/15 10:07:10 - beers-wikipedia-graph - Workflow execution finished
2023/05/15 10:07:10 - Hop - Workflow execution has ended
2023/05/15 10:07:10 - beers-wikipedia-graph - Workflow duration : 11.885 seconds [ 11.884" ]
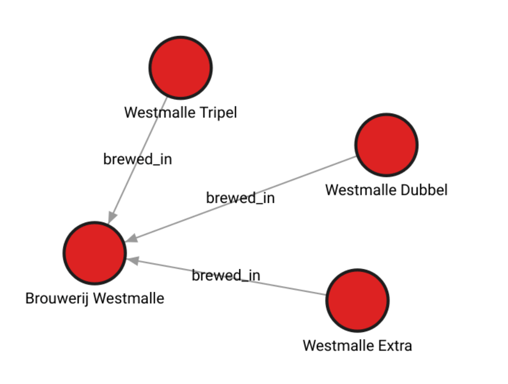
Switch back to the Memgraph console and run the query below to search for the Westmalle brewery in the graph we just created.
match p=(brewery:Brewery {name: "Brouwerij Westmalle"})-[*1..2]-(brand:Brand) return p;
Summary
The Neo4j functionality in Apache Hop turns out to work exceptionally well with other Bolt and OpenCypher-compatible graph databases.
We'll look at a couple of other OpenCypher-compatible graph databases (e.g. AWS Neptune, ) in future posts. In the not-so-distant future, we may consider working with the Apache Hop community to rebrand the Neo4j functionality to a more generic group of "graph" plugins.
Are there graph databases or graph-related topics you'd like to see covered here in more detail? Let us know in the comments...




Blog comments