
As explained in a previous post, know.bi has been working with Matt Casters (Neo4j) and our growing...
Bart Maertens

The Apache Hop (Incubating) project just released version 1.0, the first major release of the Apache Software Foundation's biggest (incubating) data orchestration and integration platform.
 Hop 1.0 is a modern data orchestration platform that works with all major data technologies, handles data at any scale and blends in with any data architecture.
Hop 1.0 is a modern data orchestration platform that works with all major data technologies, handles data at any scale and blends in with any data architecture.
This first major release is a first milestone for the Hop project and community. Worth over two years of work, Hop 1.0 provides everything data teams of all sizes and skill levels needs to be more productive than ever before.
Initially start as a fork of Pentaho Data Integration. Hop 1.0 therefore also marks the end of the beginning: upgrades are possible, but any other ties with the predecessor platform have been cut. Hop is a platform of its own, and more importantly, is more than ready for prime time.
A closer look at Hop 1.0
Architecture
Hop was designed from the ground up to be as powerful, flexible and lightweight as possible. The Hop platform consists of a small but robust and flexible kernel. All functionality is added through plugins. This architecture allows Hop to process data from IoT edge devices up to petabytes of data in the world's largest clusters.
With over 400 plugins, adding more than 20 different types of functionality, Hop offers a rich set of functionality to build data workflows and pipelines. The platform is capable of processing data in streaming, batch or hybrid modes. Additionally, Hop can be deployed on-premise, in the cloud or in hybrid architectures.
Immediately after Hop started as a fork of the Pentaho Data Integration (aka PDI or Kettle) platform in late 2019, a major refactoring and code cleanup process was started to build the current Hop architecture. Literally no file in the original code base was left untouched. Hop now starts from a clean, flexible and powerful code base and is in great shape to start building the future of data orchestration.
Visual design and a uniform set of tools
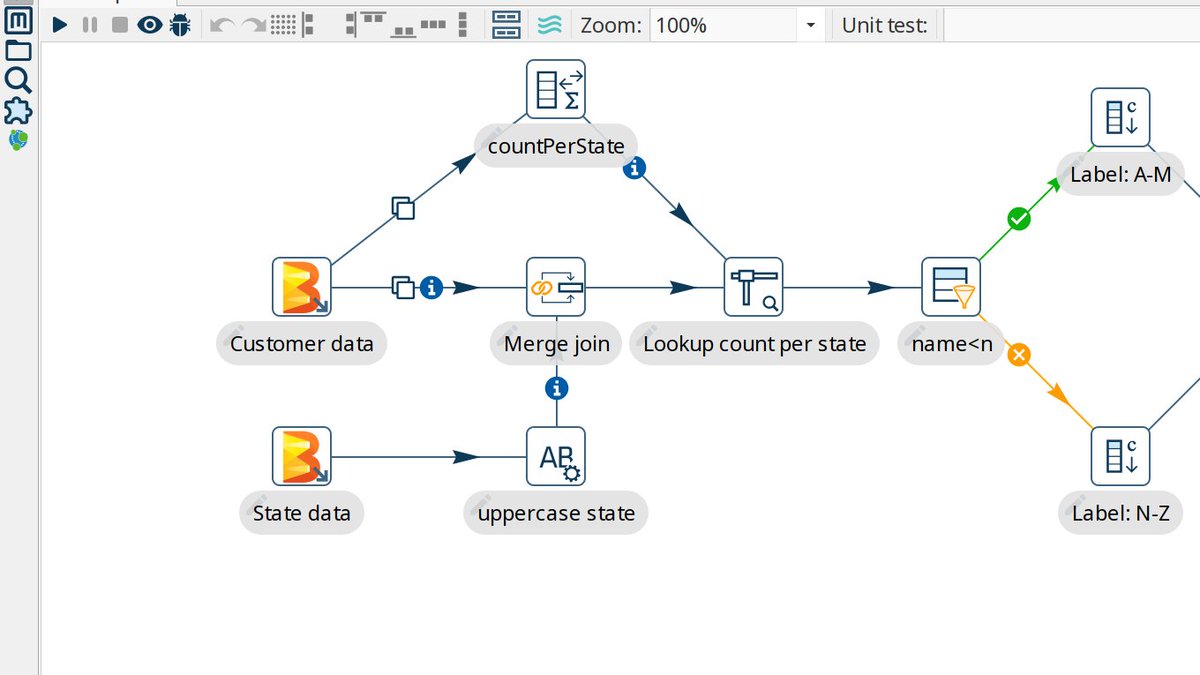
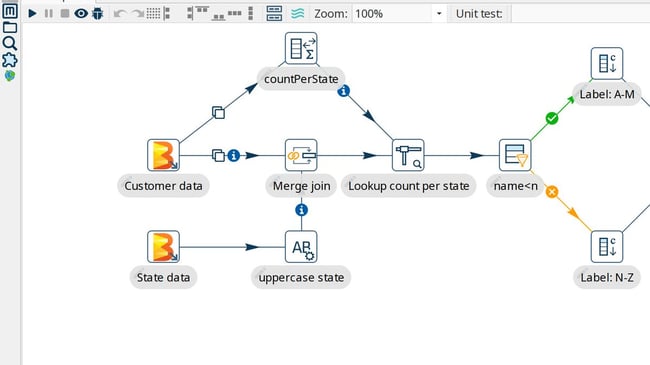
One of the flagships in the Hop platform is Hop Gui, a visual development environment (IDE) that allows data developers of all skill sets to create complex pipelines and workflows in minutes. This visual design not only allows data developers to work faster and be more productive, even more important is that it enables them to understand the flow of data through an unfamiliar workflow or pipeline at a glance. Hop Gui not only allows data developers to design, run and debug workflows and pipelines, it also provides functionality to manage metadata items like relational and NoSQL database connections, to manage files in version control, search for any metadata item in a project, and more.
Hop Gui is available on all desktop platforms (Windows, Mac OS, and Linux). Alternatively, Hop Web offers the exact same Hop Gui experience and functionality in a browser, bringing Hop one step closer to cloud-native development and deployment.
All functionality to run workflows or pipelines and to manage platform configuration is also available through a rich set of command-line tools.
Scalable by design
Hop workflows and pipelines, designed in Hop Gui, are not constrained to a single machine. Hop's runtime configurations a workflow or pipeline to run where it makes the most sense. Workflows can be executed in the native Hop engine on a local or remote machine. Pipelines have these native local and remote runtime configurations too but have the additional options to run on Apache Spark or Apache Flink clusters, or on Google Cloud dataflow over Apache Beam.
These pluggable runtimes allow Hop project teams to design their workflows and pipelines in the comfort of Hop Gui and run them where it makes the most sense. As data project grows in volume and complexity, Hop is ready to follow the data to where it can be processed most efficiently.
Projects, environments, testing for full life cycle management
Data teams typically work on a number of projects simultaneously. Hop has built-in support for projects and the environments those projects are deployed to. Projects are a logical grouping of workflows, pipelines, and other metadata items like (relational or NoSQL) database connections. Environments contain the configuration to run these projects in a given environment like development, testing or production. Switching between projects and environments in Hop Gui is as easy as selecting a new project or environment from a dropdown list. Similarly, projects and environments can be passed as arguments to the command-line tools.
This strict separation between code (projects) and configuration (environments) makes it easy to manage Hop projects and configuration (separately) in version control. The file explorer perspective has git integration to do this directly from Hop Gui. Not only can you pull, push, commit and perform other basic git operations, there's also the possibility to show a visual diff between different versions of a workflow or pipeline.
Systems fail all the time, data often is dirty or comes in unexpected formats, doesn't come at all, etc. Both workflow and pipelines allow data developers to handle errors gracefully. A workflow or pipeline that runs without errors doesn't necessarily mean your data was processed correctly. This is where Hop's pipeline unit tests come in. A unit test runs a pipeline with a given sample data set and compares the generated output to an expected (golden) data set. If the generated output matches the golden set, the test passes. If it doesn't, the test fails. Building a library of unit, integration, and regression tests guarantees that your data is processed exactly the way you expect it to.
All of these functionalities, ideally integrated into a CI/CD pipeline, enable Hop teams to build robust, scalable, and reliable data projects that can be managed throughout the entire project life cycle.
Pentaho Data Integration (Kettle) Upgrades
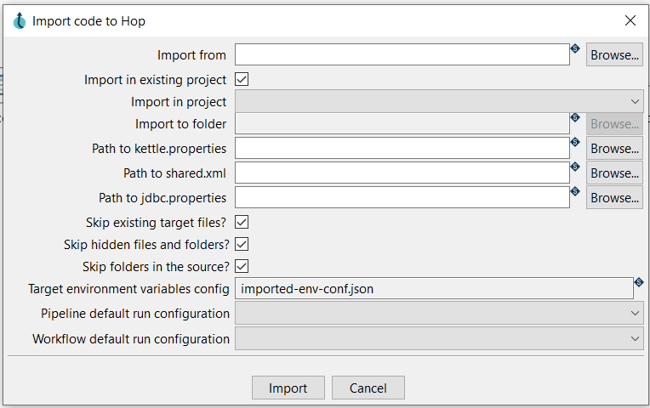
Even though Hop never intended to be compatible with Pentaho Data Integration (Kettle), the shared history makes it easy to convert existing Pentaho projects to Hop. The importer tool, available from Hop Gui and as a command-line tool, not only converts PDI jobs and transformations to Hop workflow and pipelines. The importer also converts the various configuration files (kettle.properties, shared.xml, jdbc.properties) to Hop relational database connections and environment variables and configures all imported items into a new Hop project.
With Pentaho nearing its end of life, many projects are looking for alternatives. The importer allows these projects to breathe a new life into their projects by upgrading to Apache Hop.
Cloud, Neo4j and tons of other supported platforms
Apache Hop comes with built-in support for tons of technologies and data platforms.
All major cloud storage platforms can be accessed directly through Hop's Apache VFS support. VFS, for Virtual File System, is part of the Apache Commons project and allows access to tens of data platforms over a simple URL. This is currently supported for AWS S3, Azure Blob Storage, Google Drive, Google Cloud Storage and Dropbox. Other cloud services are available for among others Google Cloud (BigQuery, BigTable, Pub/Sub) and Azure Hub Events.
Neo4j is the world's leading graph database. Graph databases excel in exploring highly connected data, and no other platform supports Neo4j better than Hop with functionality to read from and write to Neo4j, dedicated neo4j connections and models, a graph data type. Hop execution logging can be written to a Neo4j database and consulted in the Neo4j logging perspective. This logging information, in combination with lineage information about your Hop metadata and system infrastructure, offers unparalleled insights into the flow of your data.

Community
Apache incubating projects have two main responsibilities: adopt the "Apache Way" of developing and releasing software and growing the community. With Hop 1.0 as the fourth release since Hop entered the incubator, the first requirement is checked. The second requirement, growing the community, is a major success as well: Hop's social media accounts on Twitter, LinkedIn and YouTube each have hundreds of followers. Well over 200 people are actively discussing Hop functionality in the project's Mattermost chat. Local user groups started popping up in various places all over the globe, with active meetups being organized in Brazil, Spain, Italy and Japan.
A growing number of contributors is actively involved in developing and testing Hop, that number is expected to grow with this 1.0 release and the upcoming graduation as a Top Level Project. Great communities build great software. Judging by the state of the Hop community, the future looks bright.
What comes next
The Apache Hop team already started working on Hop 1.1.0. On the updated roadmap are a marketplace to enable developers to make their external plugins available to the Hop community, improved Apache Airflow integration, an improved GUI to run, preview and monitor running workflows and pipelines.
After four releases as an incubating Apache project, all known copyright and licensing issues have been fixed. The Hop name and brand was checked and approved, and the community has grown tremendously. With all necessary boxes checked, Hop is expected to graduate as an Apache Top Level project soon. This graduation means the Hop PMC (Project Management Committee) will transfer all Hop ownership and copyright to the Apache Software Transformation, effectively donating Hop to the public domain. At this point, Hop will join the ranks of projects like Apache Spark, Apache Flink, Apache Kafka and Apache Airflow and become the new household name for data orchestration and data integration.
Apache Hop and know.bi
know.bi was heavily involved with Apache Hop since the very beginning. We have two members on the Hop PPMC (Podling Project Management Committee), various other team members have contributed Helm charts, Docker improvements, code and documentation to Hop. We intend to continue and even increase our engagement with Apache Hop in the foreseeable future.
We've been working closely with a growing number of customers to upgrade their projects to Hop while phasing out our Pentaho services. We're also working closely with Lean With Data to provide support, training and coaching for customers who are taking Hop into production.


Blog comments