
Apache Hop continues to evolve quickly. After the 2.1.0 release, less than two months ago and over...
Bart Maertens


The Apache Hop community recently released Apache Hop 0.99. This will be the last release before Apache Hop 1.0 and is intended to find and fix as many bugs and issues in the code, documentation and samples. After the Hop 0.70 release in late April, the Hop team focused on making Hop as robust and stable as possible for Hop 1.0, which is expected in a matter of weeks now.
About Apache Hop
Hop started as a fork of the Pentaho Data Integration (Kettle) 8.2 code base in the summer of 2019. After about one year of work, Project Hop (as was the original name) joined the Apache Software Foundation Incubator and became Apache Hop (Incubating).
Hop, short for Hop Orchestration Platform, is a visually developed data orchestration platform with a strong focus on ease of use, life cycle management, and overall robustness. The Hop platform provides functionality to process data from and to a large variety of other data platforms, including a large variety of databases (relational, graph and other NoSQL), big data, and cloud services. Additionally, Hop has built-in unit testing functionality, git integration, project and environment management to make projects as robust and data developers as productive as possible.
Apache Hop 0.99
Since the 0.70 release in late April, the Hop team's priority has been to harden the platform for the 1.0 release. Nevertheless, there's quite a bit of new functionality and enhancements to discover and explore in 0.99. Here's a quick overview of what's new:
Hop Web
From the earliest Hop days, the goal was to support the Hop Gui on four major platforms: Windows, Mac OS, Linux, and the web. Hop Web started from the WebSpoon project, developed by Hiromu Hota. Hop Web provides the full Hop Gui experience in your browser, and now even comes with its own dark mode.
Avro and Parquet Support
Hop now supports the Avro and Parquet file formats. Both are popular serialization file formats in big data projects and both now have transforms for input and output (read and write).
Extended VFS Support
VFS (Virtual File System) is a project under the Apache Commons umbrella that provides access to a large variety of data platforms over a URI.
By default, VFS provides support for (S)FTP(S), HTTP(S), reading files directly from zip archives and lots more. Hop already added support for various cloud storage platforms like AWS S3, Azure Blog Storage, Google Drive and Google Cloud Storage earlier on.
New in 0.99 is that the VFS support is now the default option in almost all file interactions. For example, Hop projects can now live in an AWS S3 bucket or a Google Drive folder. In combination with Hop Web, this enhanced VFS support opens up a world of possibilities to deploy Hop in cloud environments.
Improved PDI/Kettle Importer
Hop and Pentaho Data Integration (Kettle) are two entirely different platforms. In the past two years, so many changes have been made to the core, engine, and other parts of the platform that not a single source file was left untouched. Hop never intended to be compatible with PDI/Kettle, but the shared history allows the Hop team to convert PDI jobs and transformations into Hop workflows and pipelines and, together with all other metadata, import these into Hop projects.
This import functionality appeared earlier this year but has now received a major update. Variables are imported into an environment file instead of on the project level, there are options to skip existing files and/or folders, VFS support was added here as well and more.
Even though Pentaho Data Integration has not been declared officially dead, the latest releases have introduced more bugs and regression than new functionality. If you're using PDI or Kettle in your data engineering or data orchestration projects and are looking for an alternative platform, Hop's importer provides an easy and straight forward way to upgrade to Hop.
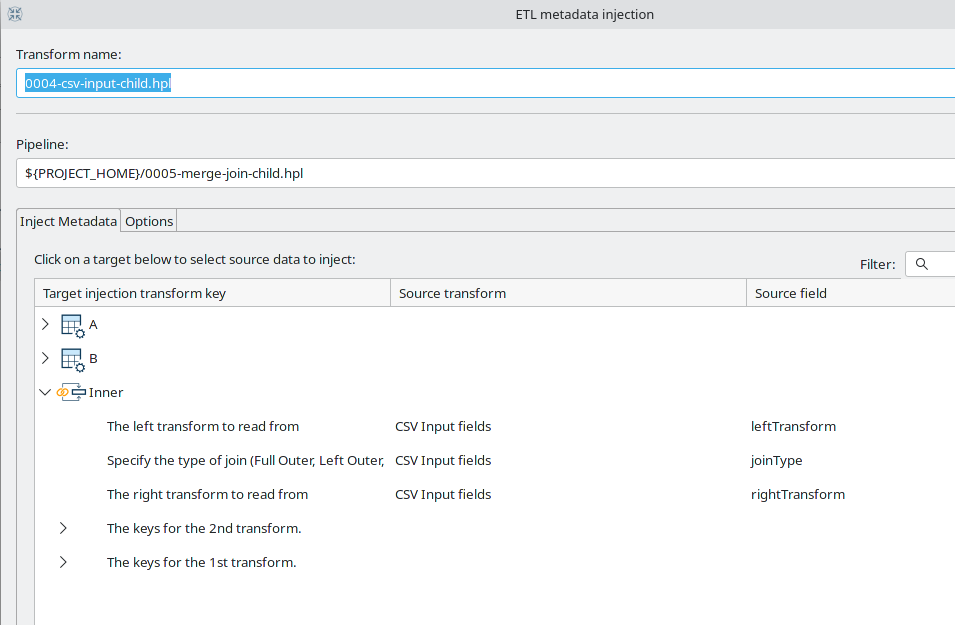
Metadata Injection Improvements
Metadata Injection already was one of the most powerful functionalities in PDI/Kettle. In short, metadata injection allows data developers to specify a pipeline template and insert the actual metadata for that pipeline in runtime. This is useful in scenarios where you need to perform the same tasks with different metadata repeatedly, for example, load a list of CSV files with different layouts to database tables.
The PDI implementation of metadata injection used two different APIs. Instead of upgrading the existing functionality when a new API was added, the old API was left in place, and new steps were developed with the new API. As part of the major refactoring and code cleanup in Hop, the old metadata API was removed. This broke metadata injection support in a lot of the transforms and needed to be re-implemented.
In the process of adding new and improved metadata support, the metadata injection transform received a facelift. A number of existing UI issues were fixed, and the template transform icons are now shown, which makes it easier for developers to see or remember what type a transform is and what its purpose is.
Translations
Hop considers translations of the user interface and the various tools a very important aspect of the platform. The Italian community worked hard to create a complete and top-notch Italian translation of the entire Hop platform, fixing a number of internationalization issues in the process.
Hop is now available in 10 languages. As Hop development has been moving incredibly fast over the last two years, not all languages are supported completely. Contributing translations is a straight forward task with a major impact and is a perfect way to start contributing to Hop. Check Hop's translation contribution guide if you'd like to add or improve support for your own language.
Documentation and Samples
From day 1, Hop treated documentation as the first class citizen it needs to be in any self-respecting software platform. With all of the development that was going on before the 0.70 release, keeping up with documentation was close to impossible.
After the 0.70 release, the amount of new functionality that was added decreased in favor of stability and bug fixes. When the development dust started to settle, the Hop community worked hard on documenting all of the functionality in the platform. The documentation is now feature complete and continues to grow in breadth and depth every week.
Community
One of the challenges all incubating Apache projects face is community growth. In short, quality of the code and the features that are implemented are the project team's responsibility, that is not where the Apache Software Foundation (ASF) primary focus is. What the ASF does care about are the legal aspect of the software to make sure all code is owned by the Apache Software Foundation (and as such by everyone), and maybe even more important, community building.
Apache Hop built a large following on social media. Many hundreds of new followers on the various social media platforms started following Hop since the 0.70 release, 2 new committers were added to the project, and the overall attention and activity around everything Hop increased significantly. User groups started to appear around the globe, there now are active user groups in (at least) Brasil, Spain, Italy, and Japan.
What's next for Apache Hop?
Hop 0.99 is intended as a release candidate for Apache Hop 1.0. There will be a couple of weeks of bug hunting, after which Hop 1.0 should see the light of day.
While preparing for the 0.99 release, the Hop team removed the last couple of hurdles in the licensing, copyright, and ownership of the source code and dependencies. With all of these issues out of the way, expect Hop to leave the incubator and become a Top-Level Project (TLP) in the not too distant future.
Hop development doesn't stop with 1.0. The Hop team released an updated roadmap with a couple of items the team will start working on once 1.0 is out the door. These include a marketplace that will allow third-party developers to publish their Hop plugins, pluggable serialization to allow workflows and pipelines to be saved in more modern file formats like JSON and YAML instead of the more outdated XML. Also on the roadmap are new services for logging and monitoring and a more generic logging perspective instead of the current Neo4j-centric version.
Apache Hop is ready to become your data engineering and data orchestration platform of choice.
know.bi and Apache Hop
know.bi has been very actively involved in Apache Hop since day 1, with active members in the Project Management Committee, as committers and contributors.
Contact us to find out more if you'd like to discover how you can use Hop in new projects, or if you'd like to discuss what a Pentaho to Hop upgrade would look like for your project.


Blog comments