
Earlier this month, the Apache Hop PMC and community released Apache Hop 1.2.0.
Bart Maertens


Apache Hop continues to evolve quickly. After the 2.1.0 release, less than two months ago and over 160+ tickets later, Apache Hop 2.2.0 is available.
Instead of being a minor with mostly bug fixes, 2.2.0 is full of new functionality and improvements. Most of what 2.2.0 brings are improvements in Hop GUI and Hop Web on one hand, Apache Beam and Google Dataflow on the other.
Hop Gui and Hop Web
Hop GUI is where most of the Hop users spend the majority of their time, developing, debugging and maintaining workflows and pipelines.
As one of the cornerstones of the Hop platform, Hop GUI continues to evolve. All functionality is available in both the desktop application (Hop GUI) and the web-based equivalent (Hop Web). This allows Hop users and developers to switch between environments and always feel right at home.
A couple of the new additions in Hop GUI/Web in 2.2.0 are:
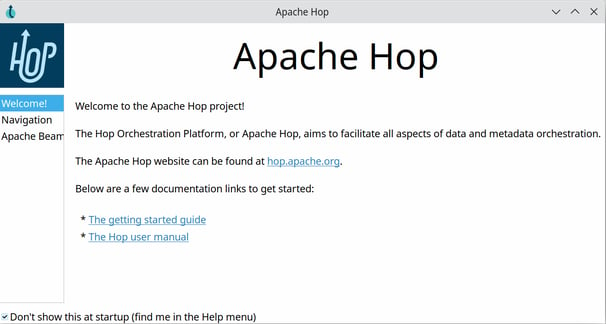
A Welcome Dialog
The new welcome dialog helps new users to walk through the first steps in Apache Hop, with pointers to the documentation, workflows and pipelines in the samples project etc.
This welcome dialog is flexible and extendable: developers can add their own information for the plugins they are building. The links in the dialog introduce a new "link" widget type developers can use in other areas of the Hop user interface.
Navigation Viewport
Overly large workflows and pipelines add a level of visual complexity, often are a performance risk, and should be avoided when possible. However, not all pipelines and workflows fit within a single screen.
Using vertical and (especially) horizontal scrollbars to move around in large workflows or pipelines has always been a painful task. To make matters worse, scrollbars behave differently on different platforms, which made it hard to guarantee consistent and useful scrollbars behavior across all platforms Hop GUI supports.
The new viewport in 2.2.0 makes navigating in Hop GUI a breeze: just drag your pointer over the viewport to scroll in any direction you want, or use your keyboard's arrow keys. Zooming in and out has also been improved and is now more consistent, with CTRL-+/= and CTRL-- to zoom in or out, CTRL-0 to return to 100% zoom.
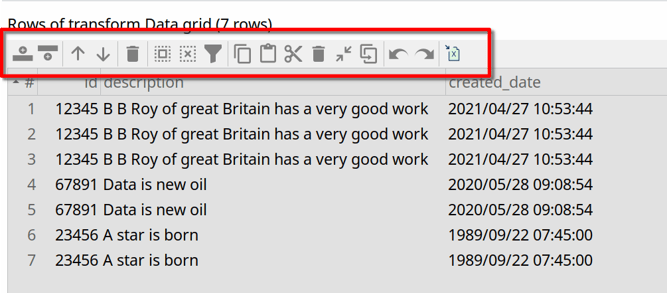
Data grid toolbars
A common task when developing workflows and pipelines is checking and manipulating data in grids.
Grid operations like row manipulations (cut/copy/paste, add/delete, move up/down), filter, remove and keep were one of the last areas in Hop GUI that used a right-click menu. That right-click menu option is still available, but all of the options have been moved to the new data grid toolbar, which gives you access to all of these commonly used functions with a single click of a button.
An additional option is to export the data in a grid to an Excel (or google sheets) spreadsheet. As power users already know, all data grids in Hop GUI can be copied to the clipboard in a tab-separated format. Since this a format most spreadsheet applications natively understand, Hop Gui data grids can be copied and pasted back and forth between the data grids and spreadsheets for faster or more advanced editing. This Excel options makes this option even more accessible.
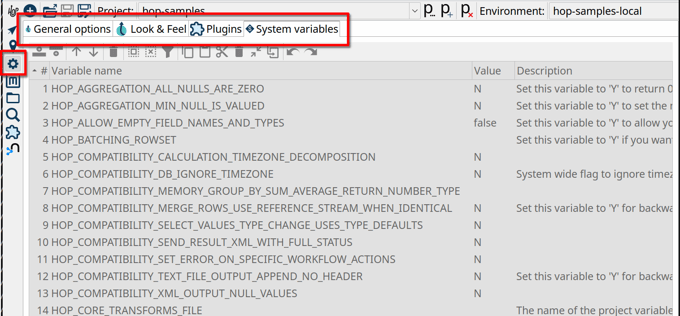
Configuration Perspective
The number of configuration options has grown with the available options that were added to Apache Hop, up to a point where configuration options became scattered. All of these have now been moved to a new configuration perspective.
Like almost everything else in Apache Hop, this configuration perspective is pluggable: developers can add their own configuration tabs to the perspective.
Hop Web
A lot of work has gone into meticulously fixing and improving lots of small issues in Hop Web.
For example, a lot of full or partial UI refreshes were harmless in the desktop Hop GUI, but caused delays, notable refreshes and other small annoyances in the Hop Web user interface. These have now been fixed, resulting in a much smoother Hop Web user experience.
The Apache Hop team started to build user interface tests for Hop Web. These, in addition to the hundreds of unit and integration tests that already are available, aim to make the Hop user interface as robust and as mature as the other parts of the Apache Hop platform.
Apache Beam and Google Dataflow
Apache Beam is a unified development layer that allows pipeline developers to build data pipelines that run on Apache Spark, Apache Flink, Google Cloud Dataflow and a number of other supported engines. Even though this unified programming interface significantly simplifies development, there is still a steep learning curve for developers who want to build data pipelines with Apache Beam. Hop's pipeline run configurations for Apache Beam allow Hop users to build their pipelines in Hop GUI, and deploy them to their Spark or Flink cluster, or to Google Cloud Dataflow without writing a single line of code.
Every Apache Hop release not only ships with the latest available Apache Beam version, there always are improvements and new functionalities.
With Hop 2.2.0, the Apache Beam run configuration for Google Cloud Dataflow now allows passing Dataflow-specific options to Dataflow jobs.
It is now also possible to schedule Google Dataflow jobs through Dataflow Flex Templates. These Dataflow templates allow you to package a Dataflow pipeline for deployment. Among other things, they let you separate pipeline design from deployment, support parameters and are version control friendly.
If you're working on a Google Dataflow pipeline, Hop GUI now lets you jump straight to the Google Cloud Console to follow up on your run pipeline execution.
As smaller improvements, the Apache Hop transform docs now have an updated indication of which transforms are known (through integration tests) to work correctly in the various Apache Beam run configurations, and the Simple Mapping transform is now supported in Apache Beam pipelines.
The Apache Beam API now also is a first-class citizen in Apache Hop, which means other transform plugins can depend on it.
Various
Apache Cassandra version 4 is now supported. Cassandra 4 brings Java 11 support, virtual tables, audit and full query logging, messaging, streaming and transient replication.
Neo4j support now includes Neo4j 5.x. This release brings increased performance, sharding, autonomous clustering and agile operations.
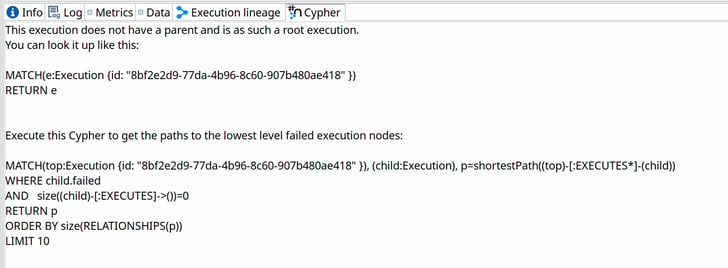
Additionally, the execution information perspective, when configured to use Neo4j for execution logging, now shows the execution lineage and Cypher tabs, similar to the initial Neo4j logging perspective.
Community
As an Apache project, the community is key for Apache Hop. The Apache Hop community continues to grow in the number of community members, geographical areas, and contributions.
Great communities build great software, a huge thank you and shoutout to everyone who was involved to make Apache Hop 2.2.0 the big release it is.
Apache Hop and know.bi
At know.bi, we were involved with Apache Hop since its inception. We are active and proud community members and contributors and will continue to do so. Get in touch if you'd like to find out more about how know.bi and Apache Hop can help you solve your data engineering and data orchestration challenges.



Blog comments