
After three months of work on 65 tickets, the Apache Hop community released Apache Hop 2.6.0...
Bart Maertens

The Apache Beam project released 2.48.0 just in time to be included in the upcoming Apache Hop 2.5.0 release.
Apache Hop has included support for Apache Beam since the very early days. With the Apache Beam Summit 2023 only one week away, now's the perfect time to take a closer look at how you can use Apache Hop to visually build data pipelines and run them on Google Cloud Dataflow through Apache Beam.
What is Apache Beam?
![]() From the Apache Beam website: "The Unified Apache Beam Model. The easiest way to do batch and streaming data processing. Write once, run anywhere data processing for mission-critical production workloads."
From the Apache Beam website: "The Unified Apache Beam Model. The easiest way to do batch and streaming data processing. Write once, run anywhere data processing for mission-critical production workloads."
Simply put: Apache Beam lets you build data pipelines that run on a number of distributed data platforms through a single, unified programming API. Pipelines that you build in Apache Beam can run on distributed engines like Apache Spark, Apache Flink or Google Dataflow with (close to) zero modification.
Do I need Apache Beam?
The short answer: if you do, you probably already know. The distributed engines, like Apache Spark, Apache Flink and Google Dataflow that Apache Beam supports are designed and built to process huge amounts of data.
If scaling up (buy a bigger machine) no longer works for your data volumes, your only choice is to scale out: buy more machines. Spark, Flink and Dataflow are distributed engines that run on clusters of machines that divide the workload to process large volumes of batch or streaming data.
If your main data sources are ERP, CRM or similar relational databases, Apache Beam is probably not your best choice. If you need to process vast amounts of streaming data (Terabytes per hour), a single machine, no matter how big, may no longer cut it, and a distributed platform is your only option. The additional cost of distributing and processing data over a cluster of machines can't be justified if your data is small enough to run on a single machine.
Apache Beam, Google Cloud Dataflow and Apache Hop
![]() Apache Beam provides SDKs to write data pipelines in Java, Python and Go, but all of those SDKs still require you to be a software developer. There has to be a better way.
Apache Beam provides SDKs to write data pipelines in Java, Python and Go, but all of those SDKs still require you to be a software developer. There has to be a better way.
Apache Hop lets citizen developers design data pipelines and workflows in Hop Gui, a visual IDE that removes as many of the technical hurdles as possible.
Hop pipelines and workflows are metadata definitions of how you want to process your data. The Apache Hop run configurations are flexible definitions of where you want to run your pipelines and workflows.
The default local run configurations let you build, test and run workflows and pipelines on the comfort of the local machine. That could be your laptop while developing and testing, a server or container where you run your scheduled workflows or pipelines, but can easily run on the distributed environments we discussed earlier.
In the next sections of this post, we'll look at building and running Apache Hop pipelines that run on Google Cloud Dataflow, Google's high-performance infrastructure for cloud computing, data analytics & machine learning. Let's dive right into it!
Setting the stage: what do you need?
We'll start by preparing a Google Cloud project, enabling the required apis, a service account and a Google Cloud Storage bucket. We'll get into the details in a moment. Just Read The Instructions for now.
Head over to the Google Cloud Console and create a project.
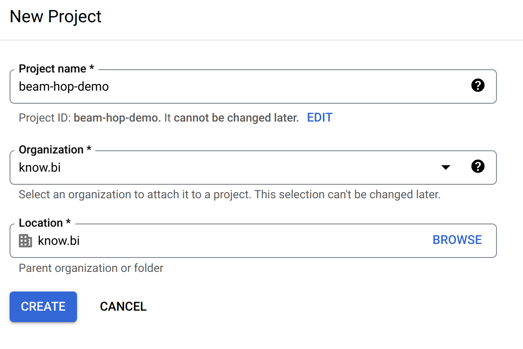
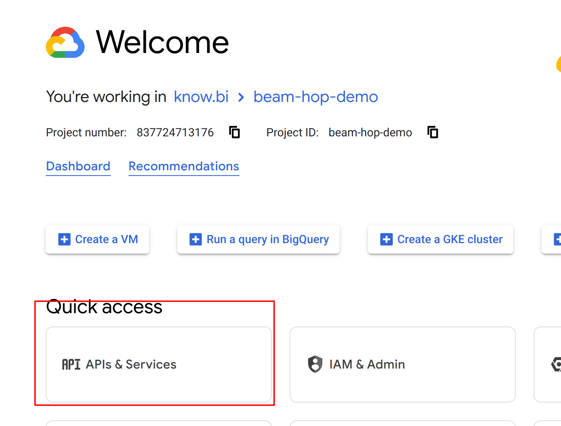
Next, make sure your project is selected and, go to "APIs & Services" and enable Google Cloud Storage API and Google Dataflow API.
In the "Credentials" tab of the Google Dataflow API home screen, you'll see the service account that was created after you enabled the API. You'll need this service account later on.
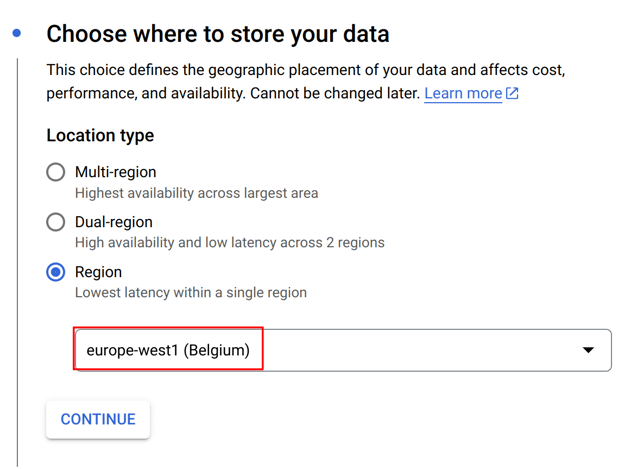
Next, we'll need to create a Google Cloud Storage bucket. Go to the Google Cloud Storage page for your project and create a bucket. we created a bucket "apache-beam-hop" in the "europe-west1 (Belgium)" region. All other settings can be left to the defaults.
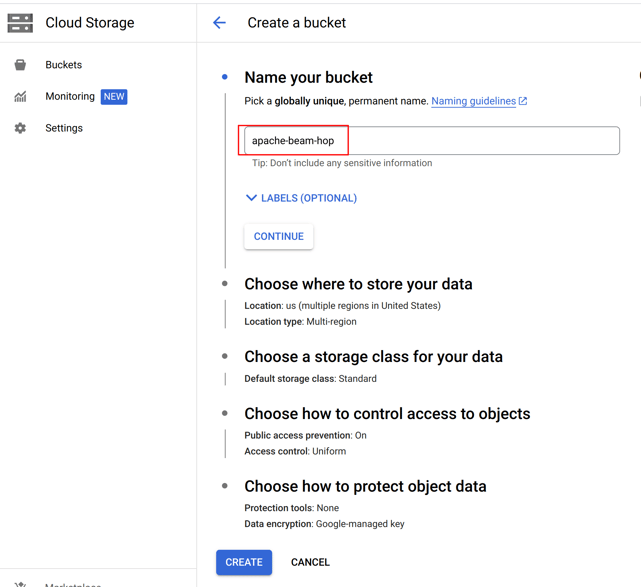
Create two folders "input" and "output" in this bucket and upload the two .txt files from the "beam/input" folder in your Apache Hop samples project to the input folder.

In the Google Cloud Storage screen, select your bucket, then "Permissions", make sure to switch to "Fine grained access control" and make sure the service account has access to your bucket.
Finally, go to the IAM & Admin -> Service Accounts page of your Google Cloud project and click on the service account that was created when you enabled the Dataflow API. In this page, go to the Keys tab, and create and download a JSON key.
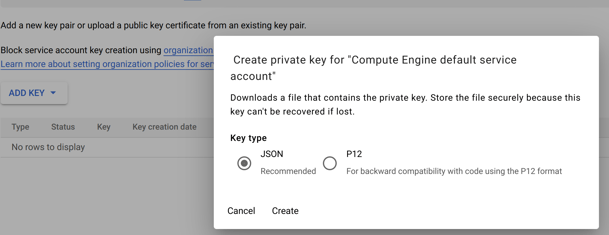
Next, we'll need to make sure your system knows how to use this key. There are multiple options, the easiest way is to set an environment variable. I used the command below on my Linux system:
export GOOGLE_APPLICATION_CREDENTIALS=<PATH_TO_MY_KEY_FILE>/beam-hop-demo-<project-hash>.json
Run the Apache Beam pipelines in the Apache Hop samples project
Apache Hop comes with a number of Apache Beam pipelines in the samples project. Let's run those in our newly created Google Cloud project.
First of all, we'll need to create a fat jar. This fat jar is a self-contained library that contains everything Apache Beam and Google Dataflow will need to run our pipelines. This jar file will be several hundreds of MB and will be uploaded to the Google Cloud Storage bucket we created earlier.
Click the Hop icon in Hop Gui's upper left corner and select "Generate a Hop fat jar". After you specified a directory and file name (we used /tmp/hop-fat.jar) to store the fat jar, Hop will need a couple of minutes to generate your fat jar.
With the fat jar in place, open the samples project in Apache Hop Gui and switch to the metadata perspective. The samples project comes with a pre-configured DataFlow pipeline run configuration that we'll change to use our newly created Google Cloud project.
Edit the run configuration to use the settings for the project we just created:

For the sake of simplicity, check the "Use public IPs?" option. Check the Google Cloud docs to learn more about configuring your project to run with private IP addresses.
In the Dataflow pipeline run configuration's variables tab, change the values DATA_INPUT, STATE_INPUT and DATA_OUTPUT variables to the bucket name you just created. Als change the filename customers-noheader-1M.txt to customers-noheader-1k.txt.
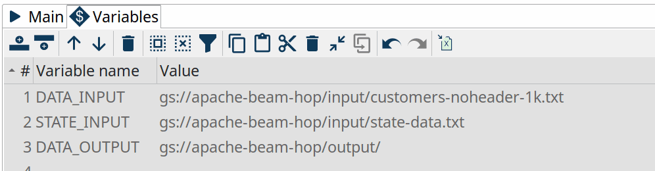
INFO: As mentioned in the introduction, distributed engines like Google Dataflow only make sense when you need to process large amounts of data. Working with small files like the customers file we're about to process doesn't make any sense in a real-world scenario. Working with small amounts of data will always be a lot faster in the native local or remote pipeline run configuration.
You now have everything in place to run your first pipeline in Google Dataflow. Go back to the data orchestration perspective and open beam/pipelines/switch-case.hpl from the samples project.
The Beam File Input and Beam File output transforms at the start of the pipeline are special Beam transforms. Both point to Beam File Definitions that you can find in the metadata perspective. The only thing these transforms do is specify a file layout and a path (the ${DATA_DIR} variable you changed earlier) where Dataflow can find the input files to read from and output files to write to. The rest of this pipeline is Just Another Pipeline.
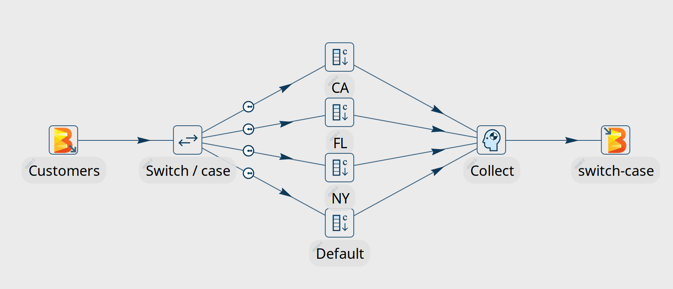
Hit the run button, choose the Dataflow run configuration and click "Launch".
Apache Hop will upload your fat jar to the staging folder in your Google Cloud Storage bucket, which will take a couple of minutes (check the "staging" folder in your bucket). When that is done, a dataflow job will be created and started. Creating the job, starting the pods and running the pipeline will take another couple of minutes.
The Dataflow job should finish successfully after a couple of minutes. Remember: distributed engines are not designed to handle small data files, the native (local or remote) pipeline run configurations will always perform better on small volumes of data.
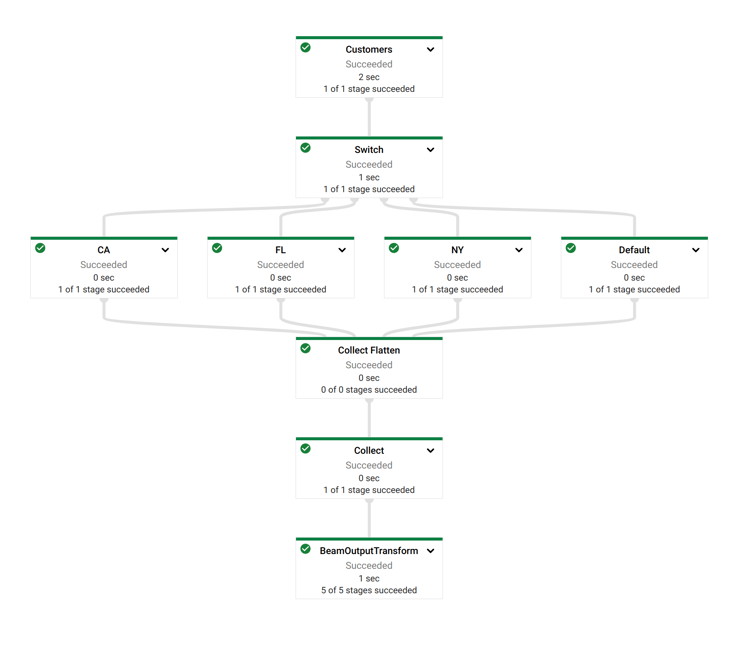
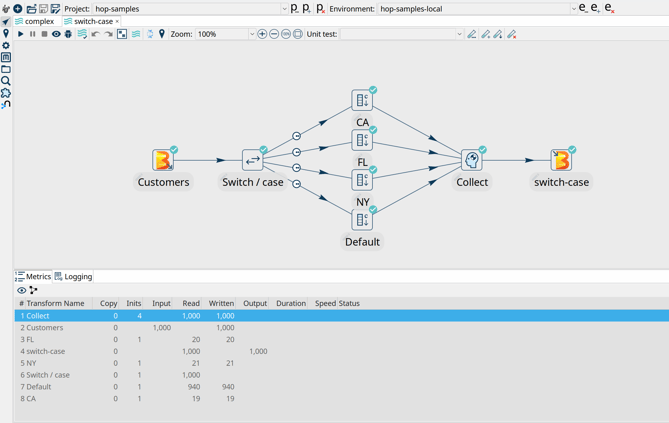
Notice how Dataflow created a job where the visual layout and the transform names are immediately recognizable from your Apache Hop pipeline.
Check the logs (at the bottom), and the cost (4th tab in the tab bar at the top of the page). The cost to run this Dataflow job was $0. Google Dataflow is free! (spoiler: it's not).
Now, switch back to Hop Gui and notice how your Switch Case pipeline has been updated with green success checks and transform metrics. The logging tab looks a little different than what you're used to from pipelines that run in the native engine. Apache Hop depends on the logging information and metrics it receives from Apache Beam, which in its turn needs to receive logging and metrics from the called distributed platform (Dataflow in this case).
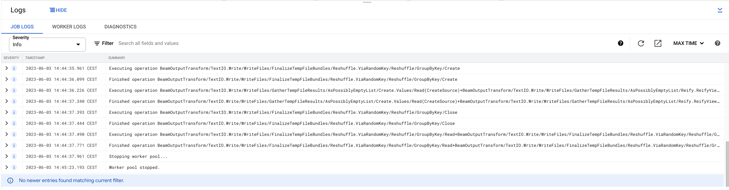
2023/06/03 15:44:18 - Hop - Pipeline opened.
2023/06/03 15:44:18 - Hop - Launching pipeline [switch-case]...
2023/06/03 15:44:18 - Hop - Started the pipeline execution.
2023/06/03 15:44:19 - General - Created Apache Beam pipeline with name 'switch-case'
2023/06/03 15:44:19 - General - Handled transform (INPUT) : Customers
2023/06/03 15:44:19 - General - Handled generic transform (TRANSFORM) : Switch / case, gets data from 1 previous transform(s), targets=4, infos=0
2023/06/03 15:44:19 - General - Transform NY reading from previous transform targeting this one using : Switch / case - TARGET - NY
2023/06/03 15:44:19 - General - Handled generic transform (TRANSFORM) : NY, gets data from 1 previous transform(s), targets=0, infos=0
2023/06/03 15:44:19 - General - Transform CA reading from previous transform targeting this one using : Switch / case - TARGET - CA
2023/06/03 15:44:19 - General - Handled generic transform (TRANSFORM) : CA, gets data from 1 previous transform(s), targets=0, infos=0
2023/06/03 15:44:19 - General - Transform Default reading from previous transform targeting this one using : Switch / case - TARGET - Default
2023/06/03 15:44:19 - General - Handled generic transform (TRANSFORM) : Default, gets data from 1 previous transform(s), targets=0, infos=0
2023/06/03 15:44:19 - General - Transform FL reading from previous transform targeting this one using : Switch / case - TARGET - FL
2023/06/03 15:44:19 - General - Handled generic transform (TRANSFORM) : FL, gets data from 1 previous transform(s), targets=0, infos=0
2023/06/03 15:44:19 - General - Handled generic transform (TRANSFORM) : Collect, gets data from 4 previous transform(s), targets=0, infos=0
2023/06/03 15:44:19 - General - Handled transform (OUTPUT) : switch-case, gets data from Collect
2023/06/03 15:44:19 - switch-case - Executing this pipeline using the Beam Pipeline Engine with run configuration 'DataFlow'
2023/06/03 15:47:25 - switch-case - Beam pipeline execution has finished.
Next Steps...
You've now successfully configured and executed your first Apache Hop pipeline on Google Cloud Dataflow with Hop's Dataflow pipeline run configuration. If you want to read a different approach to the same problem, you may want to take a look at this post and the Hop Web version by Google's Israel Herraiz.
This is just the tip of the iceberg. There are lots of transforms that are optimized for Apache Beam, and most of the standard transforms can be used in your pipelines.
We'll cover more of those options for Google Dataflow and other distributed platforms in future posts but don't hesitate to let us know in the comments or reach out if there's anything you'd like us to cover in a future post.
As always, this post has been contributed back to the Apache Hop docs as part of #3001.



Blog comments