

Neo4j is the world's leading graph database management system, designed for optimized fast...
Bart Maertens

What is Data Lineage?
Wikipedia's describes data lineage as:
"Data lineage includes the data origin, what happens to it and where it moves over time. Data lineage gives visibility while greatly simplifying the ability to trace errors back to the root cause in a data analytics process."
In short, data lineage is the process of tracking data as it flow through the applications and systems in an organization. Each operation on a data point, from its inception to its final destination (if there ever is one) is stored with the type of action, the operator, timestamp, before and after state etc.
Having this information in place can provide a number of insights that were previously impossible:
- organizations can track data issues, e.g. data quality problems, and identify the system, user and point in time where those issues originated.
- perform impact analysis: what happens when I change a column in my application databases. Where does the data from that column end up in my data warehouse? Which reports and dashboards use that data? How frequently are those reports and dashboards used? Where are those users located? How severely will they be impacted if those reports or dashboards break because of the planned modification?
- auditing, compliance: being able to track all data from the moment it enters to the moment it leaves the organization can prove to be an indispensable tool in auditing and compliance reporting. Compiling an audit or compliance report becomes as trivial as extracting (a part of) the data's life cycle.
Data Lineage in the Data Governance Operating Model
With data lineage as a tool in our belt to achieve the greater goal of an organization-wide data governance, let's have a look how we can fit data lineage into the Data Governance Operating Model as described by Collibra.
The Data Governance Operating model divides all major data management operations in three main categories we can apply to data lineage:
- structure: what is happening to my data and where do these actions happen?
- execution and monitoring: how and when are these changes applied
- organizational: who is using or operating on my data?
Data Lineage with Neo4j and Apache Hop (Incubating)
What we're looking at in data lineage are actions and changes on data. We want to find out what happens to data, where the changes happen, how and when these changes occur, and who performs the changes.
A relational database model that is able to hold all of the systems data moves through, the various states and shapes the data takes, the systems and users acting on and interacting with the data would require tens, if not hundreds of tables. For each and every request, complex joins would need to be written to walk through each and every action, state change etc.
This large number of joins is inevitable, since what we're looking at and interested in are the relationships between a data point and the systems or users that are involved in the life cycle of the data point. At its core, data lineage is a graph problem! When modeled in a graph, we need a couple of logical states, users etc, with relationships for every state change. We can walk through all the known and unknown relationships with path finding functions and algorithms without having to hand-craft or even know every path in the graph. Graphs make the entire data lineage problem a lot more manageable!
With lineage as a graph problem, graph database Neo4j and Apache Hop, as a data engineering platform with tight Neo4j integration, are obvious choices.
A sample use case: the Hop Community graph
Since the start of the project in late 2019, Apache Hop has gathered a large community of several hundreds of people who interact on social media and the Mattermost chat channel. A lot of these discussions are about new functionality or bugs in existing functionality, all of which are logged in the ASF's JIRA platform.
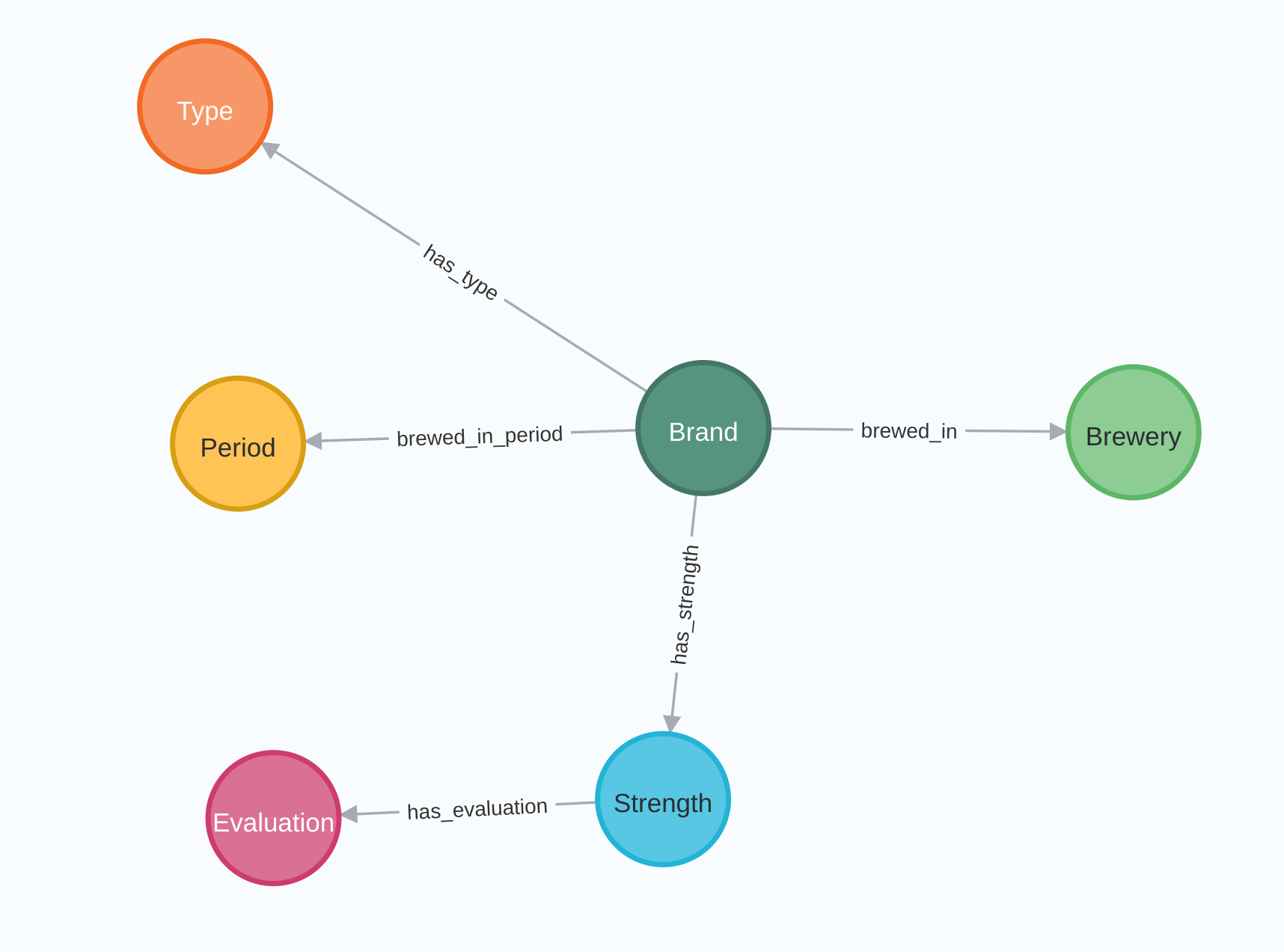
We created a sample project to load all of these chat interactions on Mattermost, all of the available JIRA issues, and linked all of the chat messages where JIRA issues are discussed. This information is loaded into a graph with the model as shown below:
In this model, we have a Hop team with a number of channels. Users post messages in each of these channels. These messages have a sequence (the 'Follows' relationship), and can mention JIRA issues. Each JIRA ticket is related to one or more components and moves through a number of states.
More information, like the users who create or work on a JIRA ticket, the state changes an issue moves through before it is closed, etc may be added in later versions of this sample project, but this already gives us a good idea of what the is going on in our discussion channels.
The Hop code, the workflows and pipelines required to load this graph, are available in our github repository.
Lineage on the Hop community graph
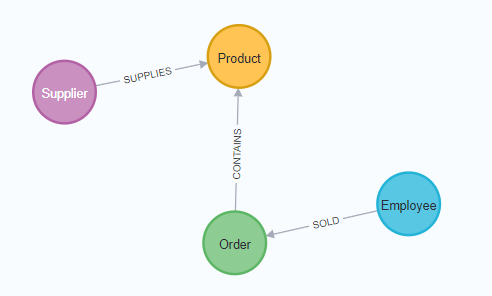
With our Hop community graph in place, we have a starting point to build a lineage graph. The components we have are:
- AWS: the Hop Mattermost server is an EC2 instance that lives in our AWS infrastructure.
- Workflows and pipelines: the Hop code that is used to load the Hop community information to Neo4j
- the Git version control system stores all operations on the code to load the Hop community graph
- execution logging: for every run of the Hop community graph, the system, load dates and times, number of rows processed etc are logged to the audit sub graph
This information gives us access to the what, where, how, when and who information we discussed earlier, and is stored in the graph model shown below:

This model can be updated as a hybrid of batch (AWS infrastructure, workflows and pipelines) and real-time (on each execution, after every git commit). With this information in place, we can start to query the system for insights into our entire architecture.
Some examples queries are:
- what are the pipelines that operate on one of my EC2 instances, in one specific AWS region or availability zone?
- where in my pipelines is the link between data points A and B created, e.g. where are our Mattermost messages linked to JIRA tickets?
- how do we process a message from the pure JSON input data to the Neo4j node to a potential link with a JIRA ticket?
- when did a particular message arrive in the Hop community graph, when was a particular change applied to the community graph?
- who are the developers that made changes that may be impacted if I change any of the AWS infrastructure?
All of the lineage information for the Hop community project was collected with the lineage project in our github repository. This repository is aimed to be a starting point for more lineage: we have code that builds nodes and relationship for relational databases (db, schemas, tables, columns), more AWS (e.g. RDS, DMS), GCP (BigQuery), Pentaho reporting and Mondrian. This repository is still work in progress, but feel free to take it for a spin and provide feedback through issues or discussions.
This post accompanies the webinar we did on data lineage with Neo4j and Apache Hop.
Google Slides
Github: Hop Community Graph repository
Github: Neo4j and Apache Hop Lineage repository
Blog comments