
This guide will teach you the process of exporting data from a relational database (MySQL) and...
This guide will teach you the process of exporting data from a relational database (MySQL) and importing it into a graph database (Neo4j). You will learn how to take data from the relational system and to the graph by translating the schema and using Apache Hop as import tools. This Tutorial uses a specific data set, but the principles in this tutorial can be applied and reused with any data domain.
This guide was inspired by the original Neo4j Northwind tutorial. We've borrowed parts of the original post for context and completeness. The actual data loading is done with the Neo4j functionality in Apache Hop.
Next week, there will be a similar post where we use the Neo4j Graph Output transform and the Neo4j Graph Model metadata object to import data into a Neo4j database.
Prerequisites:
- You should have a basic understanding of the property graph model and know how to model data as a graph.
This tutorial can be followed using an AuraDB instance and Apache Hop:
Neo4j Aura:
Neo4j Aura is free. Start on AuraDB
Alternatively, you can:
- Start a Blank Neo4j Sandbox
- Download and install Neo4j Desktop.
Apache Hop
Apache Hop is a data engineering and data orchestration platform that allows data engineers and data developers to visually design workflows and data pipelines to build powerful solutions.
As an Apache project, Apache Hop is also free. Get started with Apache Hop
About the Data Set
In this guide, we will be using the Northwind dataset, an often-used SQL dataset. This data depicts a product sale system - storing and tracking customers, products, customer orders, warehouse stock, shipping, suppliers, and even employees and their sales territories. Although the Northwind dataset is often used to demonstrate SQL and relational databases, the data also can be structured as a graph.
An entity-relationship diagram (ERD) of the Northwind dataset is shown below.
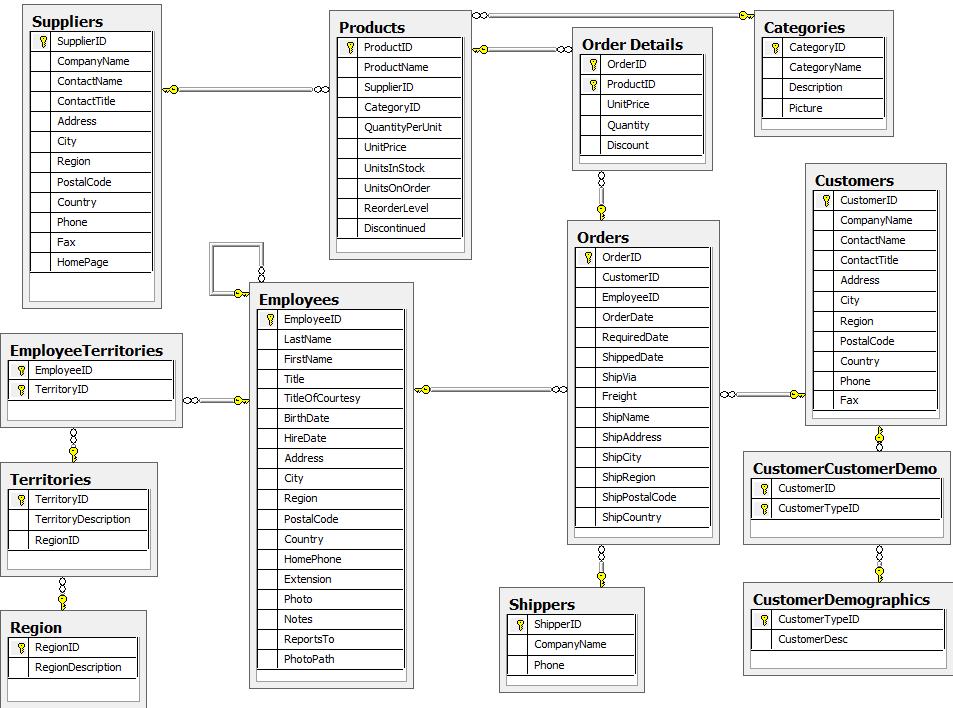
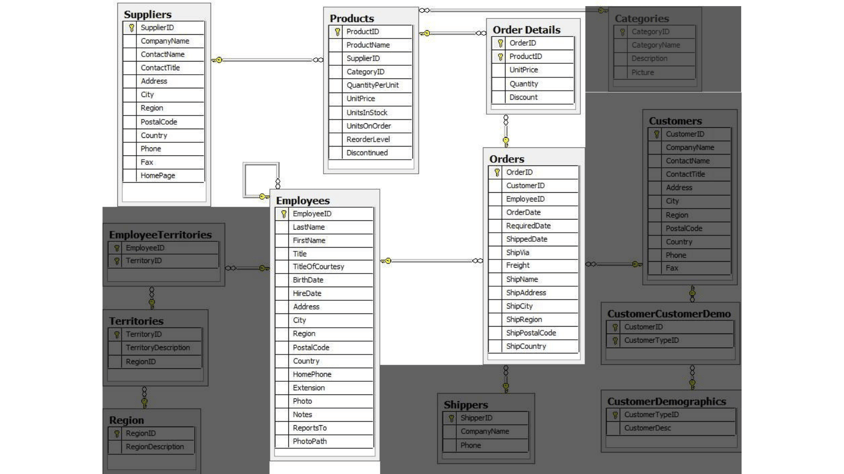
First, this is a rather large and detailed model. We can scale this down a bit for our example and choose the entities that are most critical for our graph - in other words, those that might benefit most from seeing the connections. For our use case, we really want to optimize the relationships with orders - what products were involved (with the categories and suppliers for those products), which employees worked on them, and those employees' managers.
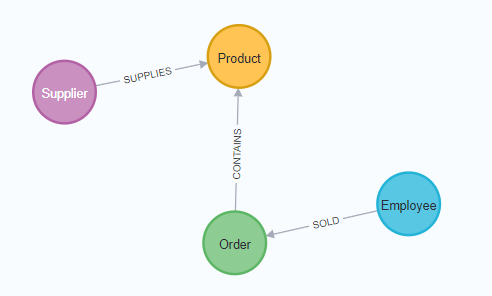
Using these business requirements, we can narrow our model down to these essential entities.
Developing a Graph Model
The first thing you will need to do to get data from a relational database into a graph is to translate the relational data model into a graph data model. Determining how you want to structure tables and rows as nodes and relationships may vary depending on what is most important to your business needs.
For more information on adapting your graph model to different scenarios, check out the modeling designs guide.
When deriving a graph model from a relational model, you should keep a couple of general guidelines in mind.
- A row is a node.
- A table name is a label name.
- A join or foreign key is a relationship.
With these principles in mind, we can map our relational model to a graph with the following steps:
Rows to Nodes, Table names to Labels
- Each row on our
Orderstable becomes a node in our graph withOrderas the label. - Each row on our
Productstable becomes a node withProductas the label. - Each row on our
Supplierstable becomes a node withSupplieras the label. - Each row on our
Employeestable becomes a node withEmployeeas the label.
Joins to relationships
- Join between
SuppliersandProductsbecomes a relationship namedSUPPLIES(where supplier supplies product). - Join between
EmployeesandOrdersbecomes a relationship namedSOLD(where employee sold an order). - Join with join table (
Order Details) betweenOrdersandProductsbecomes a relationship namedCONTAINSwith properties ofunitPrice,quantity, anddiscount(where order contains a product).
If we draw our translation out on the whiteboard, we have this graph data model.
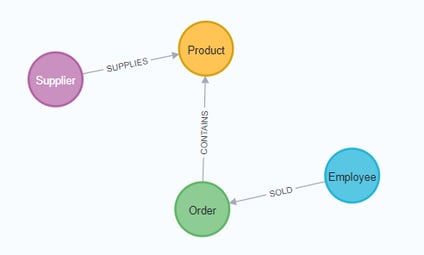
Now, we can, of course, decide that we want to include the rest of the entities from our relational model, but for now, we will keep to this smaller graph model.
How does the Graph Model Differ from the Relational Model?
- There are no nulls. Non-existing value entries (properties) are just not present.
- It describes the relationships in more detail. For example, we know that an employee SOLD an order rather than having a foreign key relationship between the Orders and Employees tables. We could also choose to add more metadata about that relationship, should we wish.
- Either model can be more normalized. For example, addresses have been denormalized in several of the tables but could have been in a separate table. In a future version of our graph model, we might also choose to separate addresses from the
Order(orSupplierorEmployee) entities and create separateAddressnodes.
Exporting and importing data to Neo4j
With Neo4j you can follow the next two steps to extract your data from your relational database and load it into your Neo4j database:
Step 1. Exporting Relational Tables to CSV
If you are working with another data domain, you will need to take the data from the relational tables and put it in another format for loading to the graph. A common format that many systems can handle is a flat file of comma-separated values (CSV).
Here is an example script to export the northwind data into CSV files.
export_csv.sql
| COPY (SELECT * FROM customers) TO '/tmp/customers.csv' WITH CSV header; COPY (SELECT * FROM suppliers) TO '/tmp/suppliers.csv' WITH CSV header; COPY (SELECT * FROM products) TO '/tmp/products.csv' WITH CSV header; COPY (SELECT * FROM employees) TO '/tmp/employees.csv' WITH CSV header; COPY (SELECT * FROM categories) TO '/tmp/categories.csv' WITH CSV header; COPY (SELECT * FROM orders LEFT OUTER JOIN order_details ON order_details.OrderID = orders.OrderID) TO '/tmp/orders.csv' WITH CSV header; |
2. Importing the Data using Cypher
You can use Cypher’s LOAD CSV command to transform the contents of the CSV file into a graph structure.
When you use LOAD CSV to create nodes and relationships in the database, you have two options for where the CSV files reside:
- In the import folder for the Neo4j instance that you can manage.
- From a publicly-available location such as an S3 bucket or a GitHub location. You must use this option if you are using Neo4j AuraDB or Neo4j Sandbox.
You use Cypher’s LOAD CSV statement to read each file and add Cypher clauses after it to take the row/column data and transform it into the graph.
Next, you will execute Cypher code to:
- Load the nodes from the CSV files.
- Create the indexes and constraints for the data in the graph.
- Create the relationships between the nodes.
The full process requires a number of manual steps to load your CSV files to Neo4j using LOAD CSV and Cypher. Check the Tutorial: Import Relational Data Into Neo4j to see how that works. Let's see how this can be done with Apache Hop.
With Apache Hop
With Apache Hop, you can do both steps with some simple pipelines/workflows, including the creation of the indexes. This may sound a bit more complex on the query and model side, but the process is a lot simpler. What's even more important is that the process of running Hop workflows and pipelines makes it possible to manage this as part of your entire process life cycle.
Creating Order nodes
 The Table Input transform read the data from the Northwind database using a MySQL connection:
The Table Input transform read the data from the Northwind database using a MySQL connection:SQL
| SELECT * FROM northwind.orders |
The Neo4j Output transform loads the Order data into the Neo4j Northwind database:
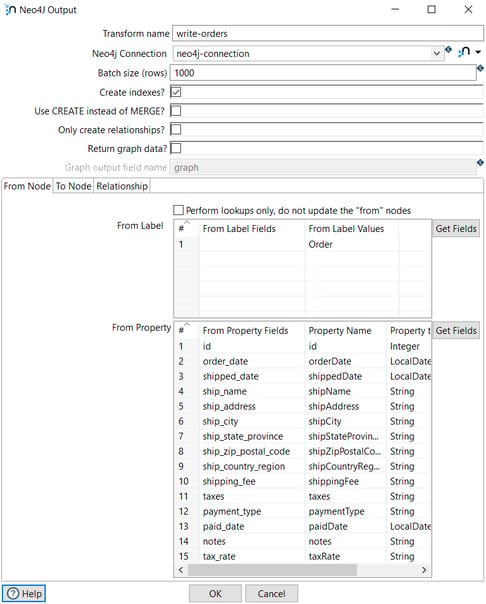

The label is Order and the properties are the fields extracted in the previous transform.
The execution of this pipeline creates 48 Order nodes in the database.
You can view some of the nodes in the database by executing this code:
Cypher:
| MATCH (o:Order) return o LIMIT 5; |
The graph view is:

The table view contains these values for the node properties:
| o |
|---|
|
{"shipCity":"Las Vegas","taxes":"0.0","shipCountryRegion":"USA","shipName":"Karen Toh","paymentType":"Check","shipAddress":"789 27th Street" ,"taxRate":"0.0","paidDate":"2006-01-15T00:00:00","shippingFee":"200.0","shipZipPostalCode":"99999","shipStateProvince":"NV","id":30,"shipped Date":"2006-01-22T00:00:00","orderDate":"2006-01-15T00:00:00"} |
|
{"shipCity":"New York","taxes":"0.0","shipCountryRegion":"USA","shipName":"Christina Lee","paymentType":"Credit Card","shipAddress":"123 4th Street","taxRate":"0.0","paidDate":"2006-01-20T00:00:00","shippingFee":"5.0","shipZipPostalCode":"99999","shipStateProvince":"NY","id":31," shippedDate":"2006-01-22T00:00:00","orderDate":"2006-01-20T00:00:00"} |
|
{"shipCity":"Las Vegas","taxes":"0.0","shipCountryRegion":"USA","shipName":"John Edwards","paymentType":"Credit Card","shipAddress":"123 12th Street","taxRate":"0.0","paidDate":"2006-01-22T00:00:00","shippingFee":"5.0","shipZipPostalCode":"99999","shipStateProvince":"NV","id":32, "shippedDate":"2006-01-22T00:00:00","orderDate":"2006-01-22T00:00:00"} |
|
{"shipCity":"Portland","taxes":"0.0","shipCountryRegion":"USA","shipName":"Elizabeth Andersen","paymentType":"Credit Card","shipAddress":"123 8th Street","taxRate":"0.0","paidDate":"2006-01-30T00:00:00","shippingFee":"50.0","shipZipPostalCode":"99999","shipStateProvince" :"OR","id":33,"shippedDate":"2006-01-31T00:00:00","orderDate":"2006-01-30T00:00:00"} |
|
{"shipCity":"New York","taxes":"0.0","shipCountryRegion":"USA","shipName":"Christina Lee","paymentType":"Check","shipAddress":"123 4th Street","taxRate":"0.0","paidDate":"2006-02-06T00:00:00","shippingFee":"4.0","shipZipPostalCode":"99999","shipStateProvince":"NY","id":34,"shippedDate":"2006-02-07T00:00:00","orderDate":"2006-02-06T00:00:00"} |
You might notice that you don’t have to import all of the field columns in the table. With your statements, you can choose which properties are needed on a node, which can be left out, and which might need to be imported to another node type or relationship.
Creating Product nodes
The pipelines for creating each node are similar:

The Table Input transform read the data from the Northwind database using a MySQL connection:
SQL:
| SELECT * FROM northwind.products |
The Neo4j Output transform loads the Product data into the Neo4j Northwind database: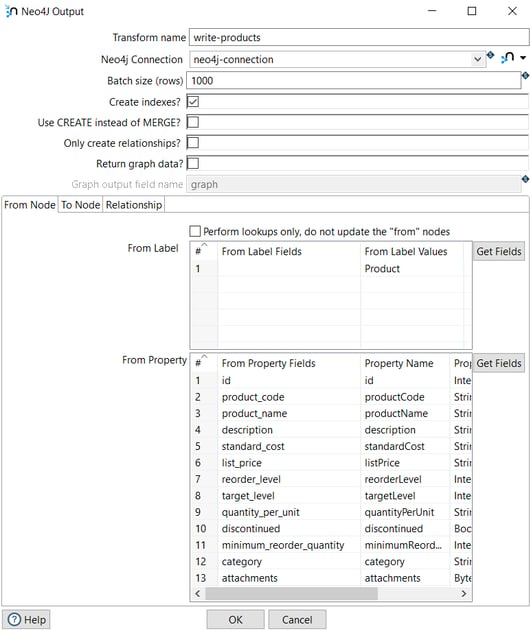
The label is Product and the properties are the fields extracted in the previous transform.
The execution of this pipeline creates 45 Product nodes in the database.
You can view some of the nodes in the database by executing this code:
Cypher:
| MATCH (p:Product) RETURN p LIMIT 5; |
The graph view is:
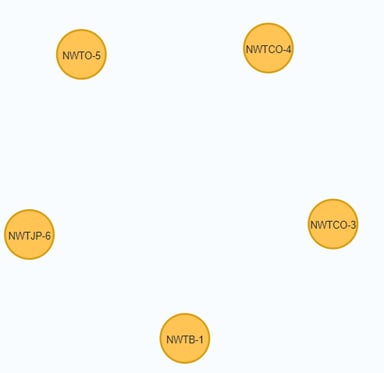

The table view contains these values for the node properties:
| p |
|---|
|
{"attachments":{},"quantityPerUnit":"10 boxes x 20 bags","discontinued":true,"minimumReorderQuantity": 10,"productName":"Northwind Traders Chai","standardCost":"13.5","reorderLevel":10, "productCode":"NWTB-1","id":1,"category":"Beverages","listPrice":"18.0","targetLevel":40} |
|
{"attachments":{},"quantityPerUnit":"12 - 550 ml bottles","discontinued":false,"minimumReorderQuantity": 25,"productName":"Northwind Traders Syrup","standardCost":"7.5","reorderLevel":25, "productCode":"NWTCO-3","id":3,"category":"Condiments","listPrice":"10.0","targetLevel":100} |
|
{"attachments":{},"quantityPerUnit":"48 - 6 oz jars","discontinued":false,"minimumReorderQuantity": 10,"productName":"Northwind Traders CajunSeasoning","standardCost":"16.5","reorderLevel":10, "productCode":"NWTCO-4","id":4,"category":"Condiments","listPrice":"22.0","targetLevel":40} |
|
{"attachments":{},"quantityPerUnit":"36 boxes","discontinued":false,"minimumReorderQuantity":10 ,"productName":"Northwind Traders Olive Oil","standardCost":"16.0125","reorderLevel":10, "productCode":"NWTO-5","id":5,"category":"Oil","targetLevel":40,"listPrice":"21.35"} |
|
{"attachments":{},"quantityPerUnit":"12 - 8 oz jars","discontinued":false,"minimumReorderQuantity":25 ,"productName":"Northwind Traders Boysenberry Spread","standardCost":"18.75","reorderLevel":25, "productCode":"NWTJP-6","id":6,"category":"Jams, Preserves","listPrice":"25.0","targetLevel":100} |
Creating Supplier nodes

The Table Input transform read the data from the Northwind database using a MySQL connection:
SQL:
| SELECT * FROM northwind.suppliers |
The Neo4j Output transform loads the Supplier data into the Neo4j Northwind database:
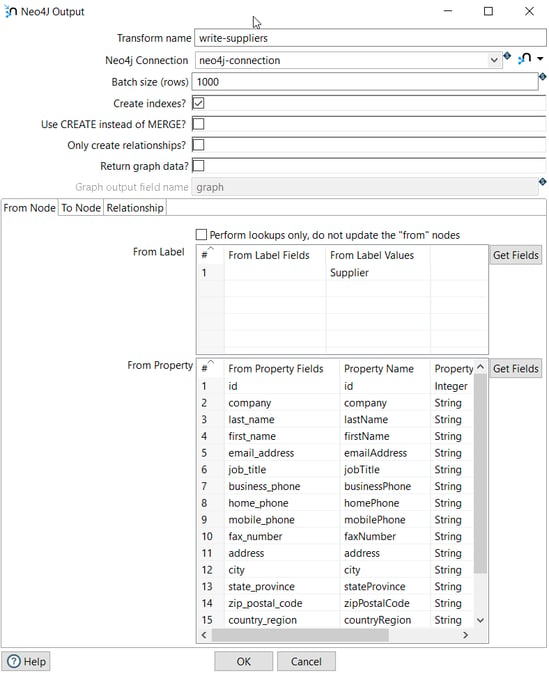

The label is Supplier and the properties are the fields extracted in the previous transform.
The execution of this pipeline creates 10 Supplier nodes in the database.
You can view some of the nodes in the database by executing this code:
Execute this cypher statement:
| MATCH (s:Supplier) RETURN s LIMIT 5; |
The graph view is:
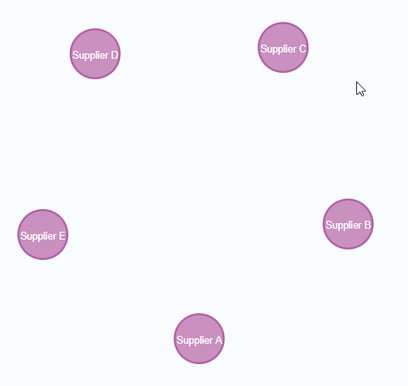

The table view contains these values for the node properties:
| s |
|---|
|
{"lastName":"Andersen","firstName":"Elizabeth A.","attachments":{},"jo |
|
{"lastName":"Weiler","firstName":"Cornelia","attachments":{},"jobTitle |
|
{"lastName":"Kelley","firstName":"Madeleine","attachments":{},"jobTitl |
|
{"lastName":"Sato","firstName":"Naoki","attachments":{},"jobTitle":"Ma |
|
{"firstName":"Amaya","lastName":"Hernandez-Echevarria","attachments":{ |
Creating Employee nodes
 The Table Input transform read the data from the Northwind database using a MySQL connection:
The Table Input transform read the data from the Northwind database using a MySQL connection:
SQL:
| SELECT * FROM northwind.employees |
The Neo4j Output transform loads the Employee data into the Neo4j Northwind database:
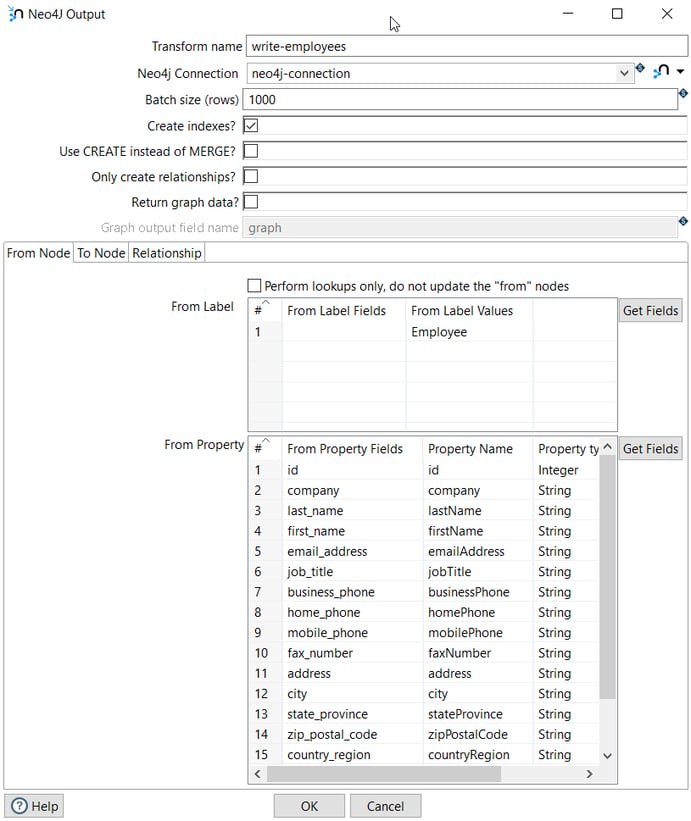

The label is Employee and the properties are the fields extracted in the previous transform.
The execution of this pipeline creates 9 Employee nodes in the database.
You can view some of the nodes in the database by executing this code:
Cypher:
| MATCH (e:Employee) RETURN e LIMIT 5; |
The graph view is:
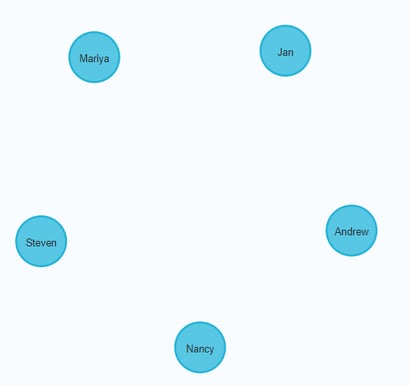

The table view contains these values for the node properties:
| e |
|---|
|
{"lastName":"Freehafer","attachments":{},"address":"123 1st Avenue","city":"Seattle","countryRegion":"USA","homePhone":"(123)555-0102","jobT |
|
{"lastName":"Cencini","notes":"Joined the company as a sales representative, was promoted to sales manager and was then named vice president of sales.","attachments":{},"address":"123 2nd Avenue","city":"Bellevue","countryRegion":"USA","homePhone":"(123)555-0102","jobTitle":"Vice |
|
{"lastName":"Kotas","attachments":{},"notes":"Was hired as a sales associate and was promoted to sales representative.","address":"123 3rd Avenue","city":"Redmond","homePhone":"(123)555-0102","jobTitle":"Sales Representative","countryRegion":"USA","stateProvince":"WA","webPage":" |
|
{"lastName":"Sergienko","attachments":{},"address":"123 4th Avenue","city":"Kirkland","countryRegion":"USA","homePhone":"(123)555-0102","jobTitle":"Sales Representative","stateProvince":"WA","webPage":"http://northwindtraders.com#Microsoft – Cloud, Computers, Apps&Gaming","emailAddress":"mariya@northwindtraders.com","zipPostalCode":"99999","faxNumber":"(123)555-0103","company":"Northwind Traders","businessPhone":"(123)555-0100","id":4} |
|
{"lastName":"Thorpe","attachments":{},"notes":"Joined the company as asales representative and was promoted to sales manager. Fluent in French.","address":"123 5th Avenue","city":"Seattle", "countryRegion": "USA","homePhone":"(123)555-0102","jobTitle":"Sales Manager","stateProvin |
Creating the indexes for the data in the graph
With Cypher, after the nodes are created, you need to create the relationships between them. Importing the relationships will mean looking up the nodes you just created and adding a relationship between those existing entities. To ensure the lookup of nodes is optimized, you will create indexes for any node properties used in the lookups (often the id or another unique value).
To do so you need to execute this code block:
Cypher:
|
CREATE INDEX product_id FOR (p:Product) ON (p.productID); CREATE INDEX product_name FOR (p:Product) ON (p.productName); CREATE INDEX supplier_id FOR (s:Supplier) ON (s.supplierID); CREATE INDEX employee_id FOR (e:Employee) ON (e.employeeID); CREATE INDEX category_id FOR (c:Category) ON (c.categoryID); |
With Apache Hop, you can include the indexes creation in the pipeline execution by selecting the Create indexes option in the Neo4j Output transform:
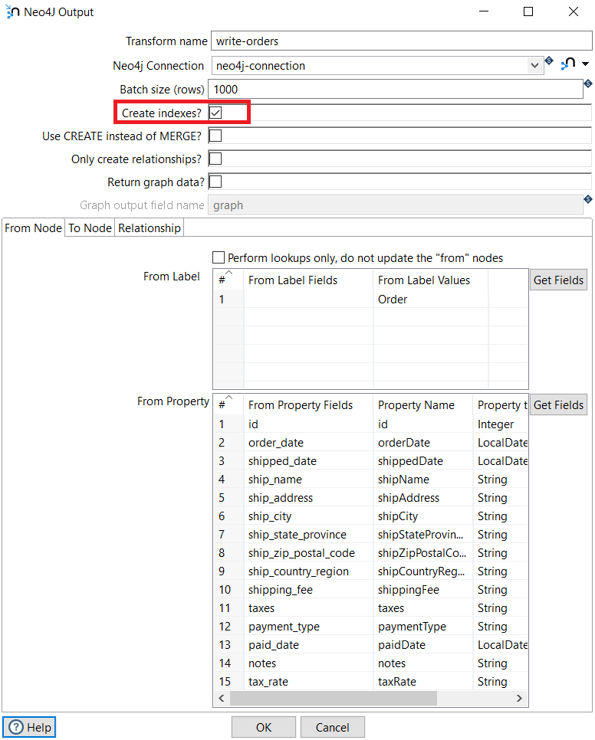

Cypher:
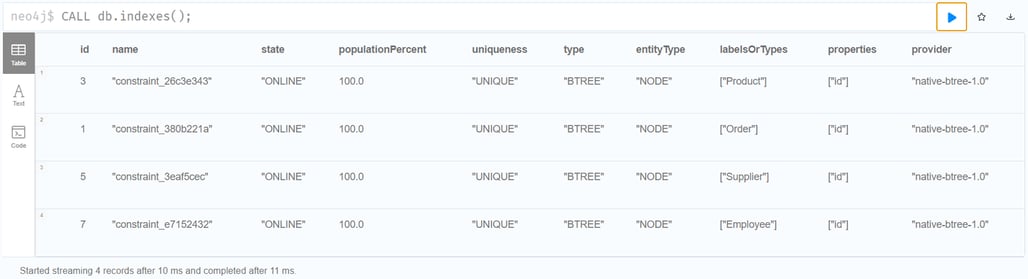
| CALL db.indexes(); |
You should see these indexes in the database:
Creating the relationships between the nodes
Next, you will create relationships:
- Between orders and employees.
- Between products and suppliers.
- Between orders and products.
Creating relationships between Orders and Employees
With the initial nodes and indexes in place, you can now create the relationship between orders and employees.

The Table Input transform read the data from the Northwind database using a MySQL connection:
SQL:
| SELECT * FROM northwind.orders |
In this case, you only need to extract the data from the orders table because the employee_id is a foreign key and you can get the relationship.


The Neo4j Output transform loads the relationship data into the Neo4j Northwind database.
In this case, the three tabs are configured as follows:
In the first tab (From Node), we specify the node from which the relationship starts (Employee).
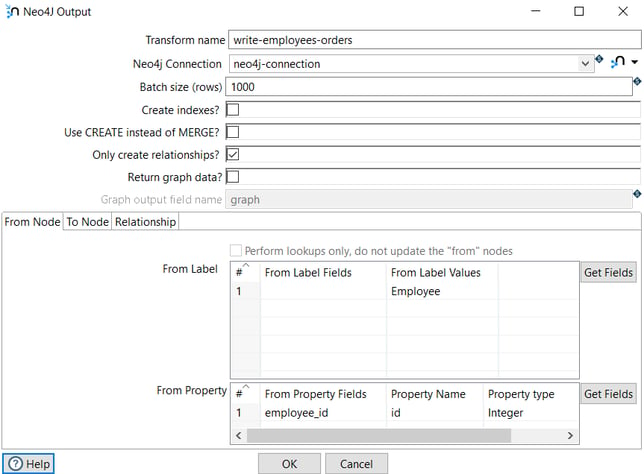

The label is Employee and the property to create the relationship is employee_id.
The From Property Fields is employee_id extracted from the database in the previous transform and in Property Name we specify the field name in the node.
In the second tab (To Node), we specify the destination node of the relationship (Order).
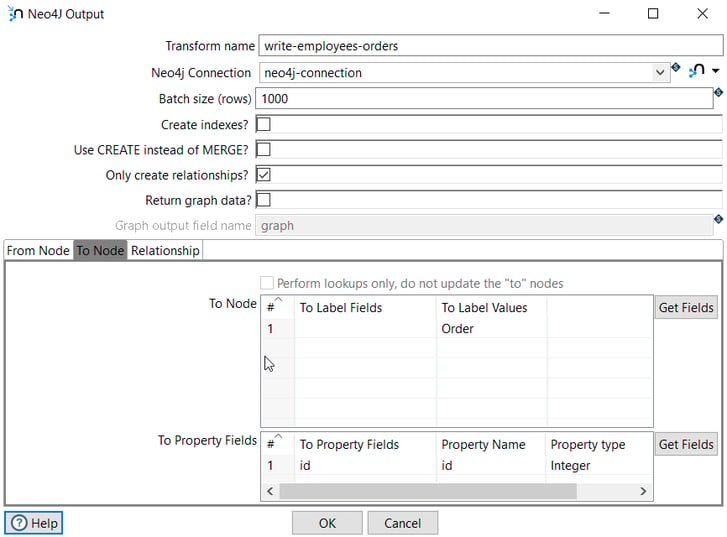

The label is Order and the property to create the relationship is id.
The From Property Fields is id (the Order id) extracted from the database in the previous transform and in Property Name we specify the field name in the node.
Finally, in the Relationship tab, we specify the relationship (SOLD).
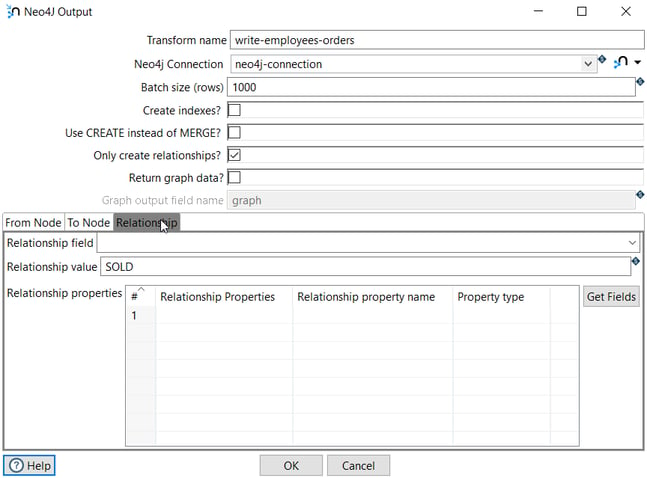

The execution of this pipeline creates 48 SOLD relationships in the graph database.
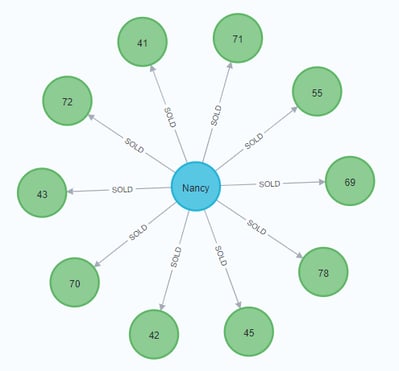
You can view some of them by executing this code:
Cypher:
| MATCH (o:Order)-[]-(e:Employee) RETURN o,e LIMIT 10; |
Your graph view should look something like this:

Creating relationships between Suppliers and Products
The Table Input transform read the data from the Northwind database using a MySQL connection:
SQL:
| SELECT * FROM northwind.products |
In this case, you only need to extract the data from the products table because the suppliers_ids is a foreign key and you can get the relationship.
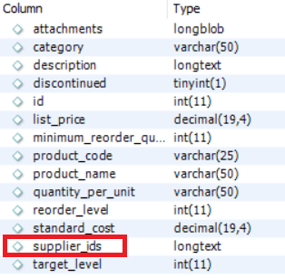

The next group of pipelines is used to separate the suppliers_ids list in rows because this field is a list instead of an Integer value:
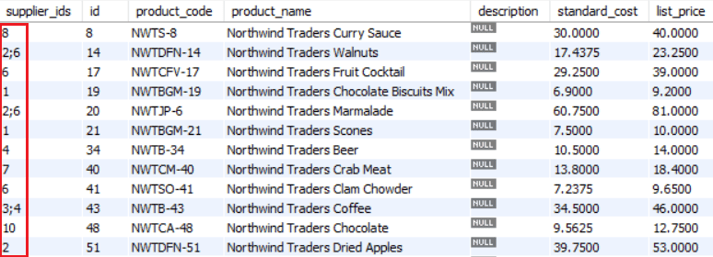

 The Neo4j Output transform loads the relationship data into the Neo4j Northwind database.
The Neo4j Output transform loads the relationship data into the Neo4j Northwind database.In this case, the three tabs are configured as follows:
In the first tab (From Node), we specify the node from which the relationship starts (Supplier).
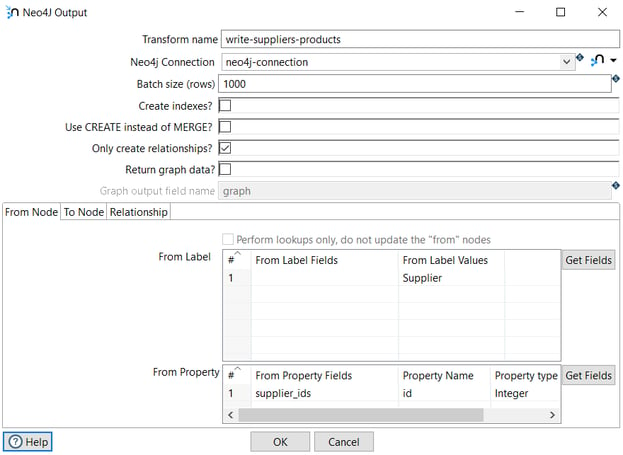

The label is Supplier and the property to create the relationship is supplier_ids.
The From Property Fields is supplier_ids extracted from the database in the previous transform and in Property Name we specify the field name in the node.
In the second tab (To Node), we specify the destination node of the relationship (Product).
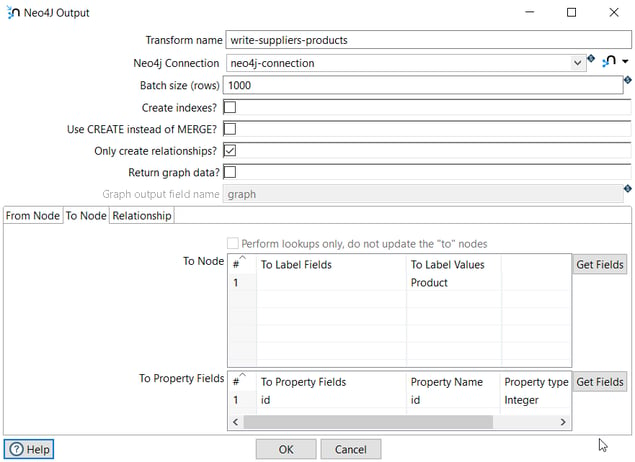

The label is Product and the property to create the relationship is id.
The From Property Fields is id (the Product id) extracted from the database in the previous transform and in Property Name we specify the field name in the node.
Finally, in the Relationship tab, we specify the relationship (SUPPLIES).
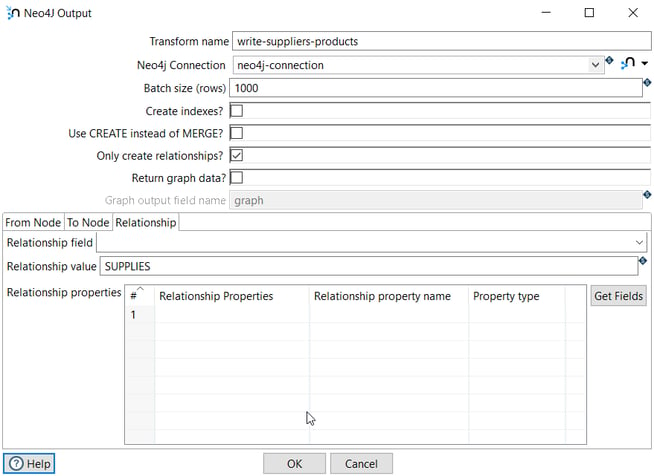

The execution of this pipeline creates 50 SUPPLIES relationships in the graph database.
You can view some of them by executing this code:
Cypher:
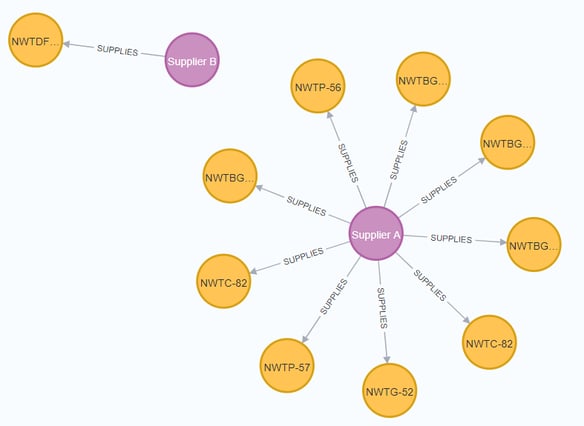
| MATCH (s:Supplier)-[]-(p:Product) RETURN s,p LIMIT 10; |
Your graph view should look something like this:

Creating relationships between Orders and Products
With the initial nodes and indexes in place, you can now create the relationship between orders and employees.

The Table Input transform read the data from the Northwind database using a MySQL connection:
SQL:
| SELECT * FROM northwind.order_details |
In this case, you only need to extract the data from the order_details table. This table contains the relationship between Orders and Products.
The Neo4j Output transform loads the relationship data into the Neo4j Northwind database.
In the first tab (From Node), we specify the node from which the relationship starts (Order).
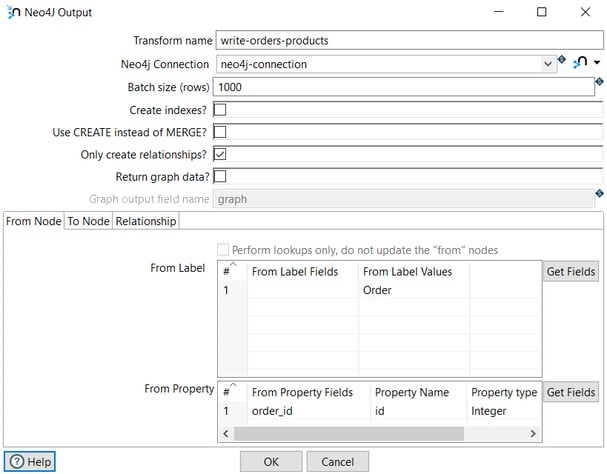

The label is Order and the property to create the relationship is order_id.
The From Property Fields is order_id extracted from the database in the previous transform and in Property Name we specify the field name in the node.
In the second tab (To Node), we specify the destination node of the relationship (Product).
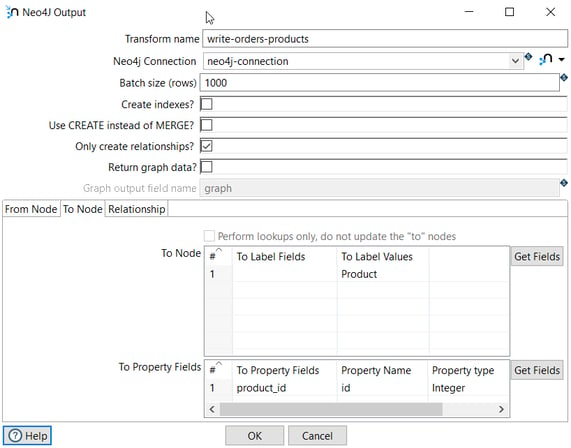

The label is Product and the property to create the relationship is product_id.
The From Property Fields is id (the Product id) extracted from the database in the previous transform and in Property Name we specify the field name in the node.
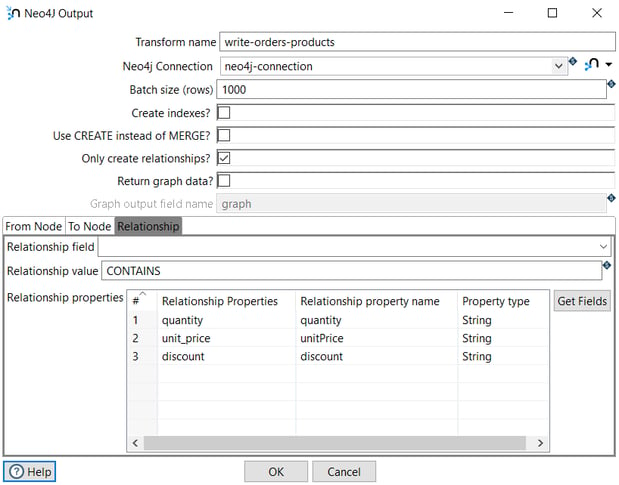
Finally, in the Relationship tab, we specify the relationship (CONTAINS) and the relationship properties:
- quantity
- unit_price
- discount
 The execution of this pipeline creates 58 CONTAINS relationships in the graph database.
The execution of this pipeline creates 58 CONTAINS relationships in the graph database.You can view some of them by executing this code:
Cypher:
| MATCH (o:Order)-[]-(p:Product) RETURN o, p LIMIT 10; |
Your graph view should look something like this:
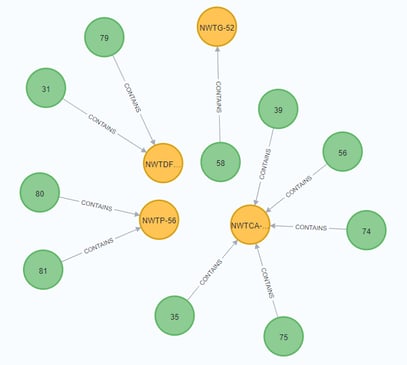

And if you run the following code block to get 30 nodes from the graph you can see the different relationships:
Cypher:
| MATCH (n)-[]-(m) RETURN n, m LIMIT 30; |
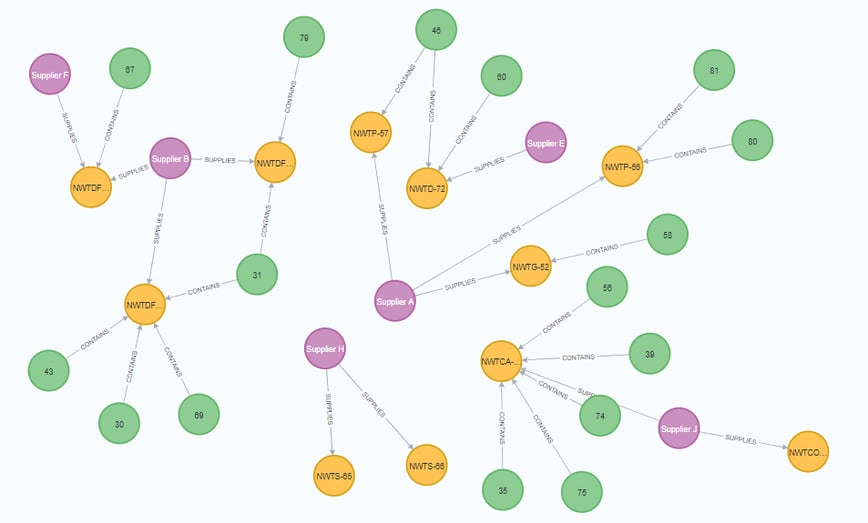
Run all the pipelines
We created 3 workflows to run de pipelines. The first one runs all the pipelines that create the nodes:

The second one runs all the pipelines that create the relationships:

And the main workflow runs the previous workflows. By running this workflow you will load all the data in your Neo4j database.
 Next, you will query the resulting graph to find out what it can tell us about our newly-imported data.
Next, you will query the resulting graph to find out what it can tell us about our newly-imported data.
Querying the Graph
We might start with a couple of general queries to verify that our data matches the model we designed earlier in the guide. Here are some example queries.
Execute this cypher statement:
| //find a sample of employees who sold orders with their ordered products MATCH (e:Employee)-[rel:SOLD]->(o:Order)-[rel2:CONTAINS]->(p:Product) RETURN e, rel, o, rel2, p LIMIT 25; |
Results:
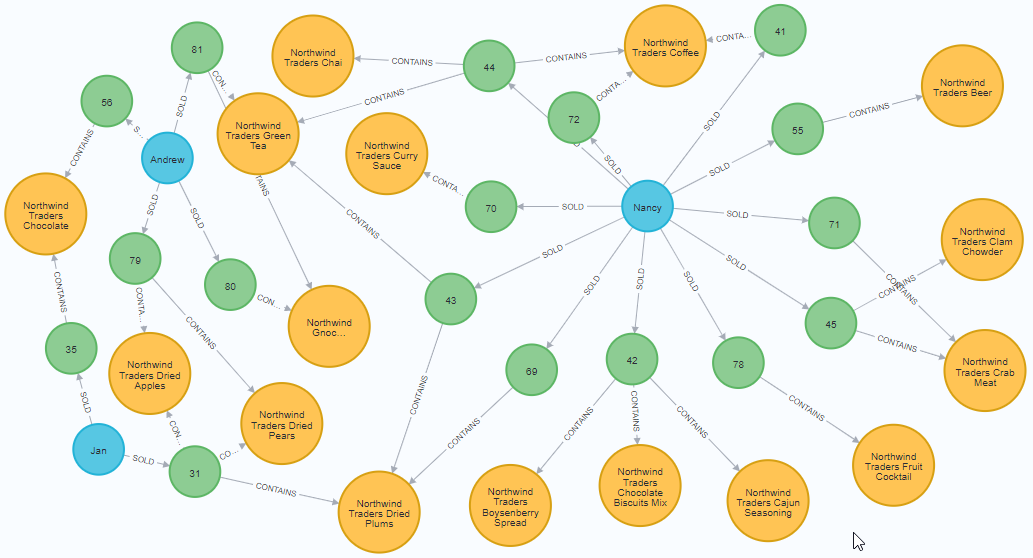

Execute this cypher statement:
| //find the supplier and category for a specific product category MATCH (s:Supplier)-[r1:SUPPLIES]->(p:Product {category: 'Candy'}) RETURN s, r1, p |
Results:
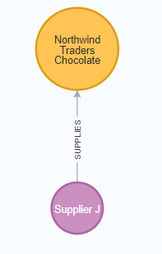

Once you are comfortable that the data aligns with our data model and everything looks correct, you can start querying to gather information and insight for business decisions.
Which Employee had the Highest Cross-Selling Count of 'Candy' and Another Product?
Execute this cypher statement:
| //find the supplier and category for a specific product category MATCH (s:Supplier)-[r1:SUPPLIES]->(p:Product {category: 'Candy'}) RETURN s, r1, p |
Looks like employee No. 4 was busy, though employee No. 2 also did well! Your results should look something like this:
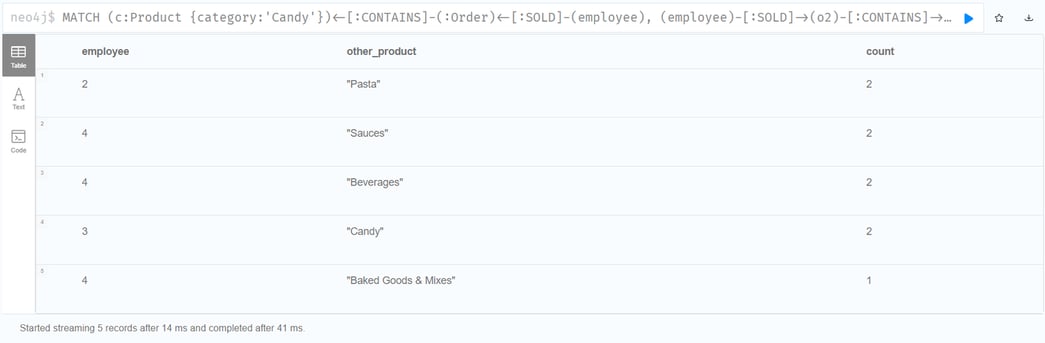
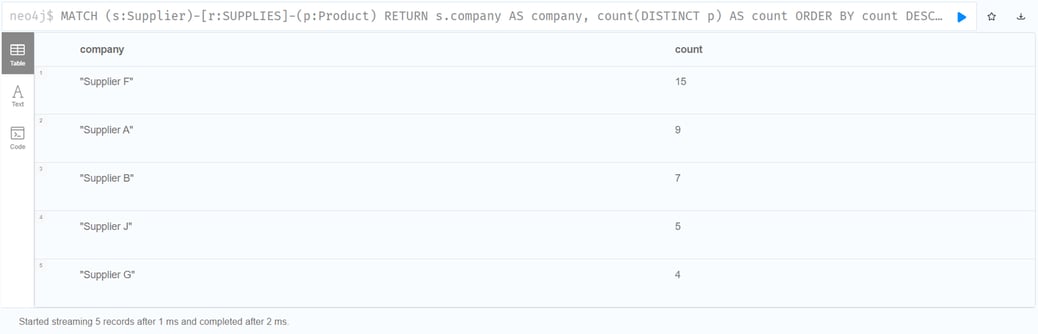
Which Suppliers supply the Highest Number of Products?
Execute this cypher statement:
| MATCH (s:Supplier)-[r:SUPPLIES]-(p:Product) RETURN s.company AS company, count(DISTINCT p) AS count ORDER BY count DESC LIMIT 5; |
Want to find out more? Download our free Hop fact sheet now!



Blog comments