Bart Maertens

Why would you upgrade your Pentaho projects to Apache Hop?
Before going into the details of how you should upgrade to Apache Hop, let's have a look at a couple of reasons why upgrading to Apache Hop is a good idea. We'll look at why it helps you to work with a platform that is actively innovating, is truly open source, and has an active community.
Work with an innovative platform
Since Apache Hop started as an Incubating project at the Apache Software Foundation back in 2020 and graduated in late 2021, the project has built release after release. There have been 5 Apache Hop releases in 2022 alone, and 2 releases in 2023 so far. The latest release at the time of writing is 2.4.0, with 2.5.0 expected in late May 2023.
Installation size: Apache Hop used to be a lot smaller than Pentaho Data Integration. That changed with PDI 9.4, where a significant size reduction was achieved by cutting out the Big Data plugin. Still, at a download size of just over 650MB, Apache Hop 2.3 is still pretty far away from the 2GB+ download sizes of PDI until 9.2. If installation size matters and you don't need to run your Hop projects on Apache Spark, Apache Flink, or Google Dataflow, removing the Apache Beam plugin cuts Hop's installation size in half.
Performance: Apache Hop is a lot faster than Pentaho Data Integration. Hop GUI, the visual IDE to develop pipelines and workflows and equivalent to Spoon in PDI, starts up in just a couple of seconds. Containers to run workflows and pipelines are even faster, requiring just one or two seconds to start. Performance benchmarks have not yet been built, but the community often sees a performance improvement after upgrading from PDI to Apache Hop. Let us know in the comments if you'd like to see a benchmark comparing PDI vs Apache Hop performance.
Flexibility: Apache Hop is flexible by design: all of the functionality is built as plugins that can be added by unzipping a plugin to your Hop folder or can be removed by deleting a plugin folder from your Hop installation. Hop GUI is available as a desktop or web-based application, there are various container images for short-running or long-running (Hop Server) scenarios, with or without Apache Beam, for Hop Web, etc.
Functionality: since the start of the project in 2019, metadata management has been drastically improved, and tons of functionality has been added to Apache Hop. A lot of new transforms and actions have appeared, and Apache Hop integrates a lot better with existing data architectures.
Some of the highlights of the new functionality that Apache Hop brings are
- Projects and environments: build your projects and configure environments. Switching to a new environment configuration is as easy as selecting an item from a dropdown or specifying a command-line parameter. Check our Getting Started guide to learn more about setting up your Apache Hop projects and environments to get started on the right track.
- Unit tests: you not only want to know if your workflows and pipelines ran correctly. Even more importantly, you want to know whether they processed your data correctly. Comparing the generated results to a golden data set in your unit tests allows you to do just that directly in Apache Hop. Read our unit testing post to learn how to build unit tests in Apache Hop.
- Integrated search: search all of your project's metadata or all of Hop to find a specific metadata item, all occurrences of a database connection for example.
- Container and cloud support: Hop comes with a pre-built container image for long-lived (Hop Server) and short-lived (Hop Run) scenarios. Additionally, Access to cloud storage and a growing number of cloud services is available in Hop.
- Pluggable runtimes allow you to run your workflows and pipelines where it makes the most sense: locally or remotely in the native engine, but also on Apache Spark, Apache Flink, Google Dataflow and AWS EMR through Apache Beam.
Work with a truly open source platform
As an Apache project, open source is at the core of Apache Hop. The entire development process, feature requests, bug reports and roadmap of Apache Hop are truly open source.
The source code for all Apache projects is owned by the Apache Software Foundation, which means it's free and in the public domain forever.
The roadmap and development for Apache projects are driven by a community with a democratic decision process: all discussions happen on publicly available mailing lists and all decisions are made through voting rounds. Over 50 people from numerous companies have contributed to Apache Hop over the past couple of years, without any of them "owning" Apache Hop.
In contrast, Pentaho Data Integration is open source in name. The development, feature requests, bug fixes and roadmap are driven and decided upon by a single company.
Work with a platform that has an active community
Apache Hop is designed and developed by an active and growing community. This global community of Apache Hop developers, contributed, testers and users is growing fast.
There is an increasing number of active user groups in Brazil, Spain, Italy, Japan, Germany, the Benelux and other places. The Hop community tests, discusses and criticizes new and existing functionality in Hop, pushing the development continuously forward.
Hop as a project has a very low bar of entry: the Hop community considers almost everything a contribution: obviously source code is one of them, but so are documentation, bug reports, community building, even discussions and (constructive) criticism are considered contributions.
Migration or upgrade?
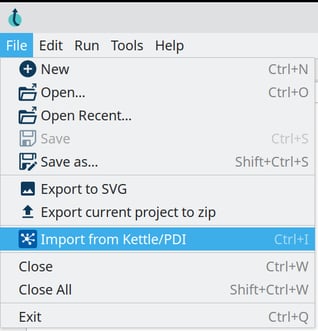 Now, how do you get from PDI to Apache Hop?
Now, how do you get from PDI to Apache Hop?
Installing Hop is easy. Check our post on how to get started with Apache Hop according to best practices to make sure you hit the ground running before we move on to the actual upgrade.
Converting your existing Pentaho Data Integration projects to Apache Hop is as simple as selecting 'File -> Import from PDI/Kettle' in Hop Gui.
However, since Hop is an entirely new platform, things work a little differently under the hood. Metadata is managed much more tightly in Hop than it is in PDI, the concepts of projects and environments are new, as are unit tests and more.
All of that is managed in the import process: a new Apache Hop project is created (or you can import into an existing project), and database connections are extracted from each and every individual job and transformation and created at the project level.
If you want to get the most out of it, an upgrade to Apache Hop is more than just the initial code conversion.
Let's walk through 7 key points that will make your switch from Pentaho Data Integration to Apache Hop not just a migration but a true upgrade.
7 key points for a successful upgrade to Apache Hop
- Perform a pre-upgrade audit.
- Manage expectations.
- Upgrade in phases.
- Code freeze while upgrading.
- Apply best practices.
- Test the upgrade.
- Train and coach the customer.
1. Pre-upgrade audit
Converting PDI/Kettle jobs and transformations to Apache Hop workflows and pipelines is trivial. Upgrading an entire project that has evolved and grown over many years, however, is not without risk. Over time, your jobs and transformations may have built up some technical debt and may just not be as clean as you think they are.
What should you audit?
A pre-upgrade audit detects as many unpleasant surprises as soon as possible, ideally before you even start the upgrade process.
Apache Hop manages metadata much more tightly than Kettle/PDI, so that's where your focus should be. In general, the more you know about a project before you start the upgrade, the better.
A number of useful checks:
- Database connections: how are connections defined? which connections are unused or need to be merged?
- Unsupported steps: Almost all of the Pentaho functionality is available in Apache Hop. A limited number of steps (e.g. Formula, Pentaho Report Output) are not available in Hop, mainly to licenses that make them incompatible with the Apache License. Does your project use any third-party plugins? Identify as many as possible before you start and check what your options are (e.g. the rewritten, faster, and more Excel-like Formula transform).
- Hard-coded values for file and folder paths, email settings, etc should be moved to variables. Your Apache Hop project should contain nothing but code, all configuration values (your configuration) should go to environments. Check our guide on how to set up your Apache Hop projects and environments for more information.
- Source code in Javascript and User Defined Java Class steps that use Pentaho code references will need to be refactored to Apache Hop.
- Optimize where possible: replace copy-to-result loops with pipeline or workflow executors, and use metadata injection where possible. Limit the scope for the upgrade to the actual upgrade, but identify non-trivial code optimization and refactoring for follow-up projects.
Building a library of checks and analyzing the results of those checks will help you detect any possible issues as soon as possible.
If you need help in building these checks, feel free to reach out. We have the tools to check your project(s) for any possible stumbling blocks and are happy to help. We even have a complete pre-upgrade check to help you find out how ready your project is for a flawless Apache Hop upgrade.
2. Manage expectations
Make sure you and all the project stakeholders are on the same page about the scope of the upgrade.
Limited architectural changes and code refactoring can be included, but make the project more complex and harder to test. The upgrade is not the time to go through major architectural changes, but is a good opportunity to identify the changes you may want to make to your data architecture after the initial upgrade.
Set the upgrade stage correctly
Apache Hop has evolved into a platform that is completely different from PDI/Kettle. One aspect of an upgrade is the code conversion from jobs and transformations to workflows and pipelines. However, just about everything else in a project's organization is different in Hop than in PDI/Kettle.
A couple of quick guidelines for a successful upgrade are:
- Greenfield environments: separate the PDI/Kettle and Apache Hop environments. Use containers and DevOps principles to automate installation and configuration where possible.
- Version control everything: version your code (pipelines, workflow, metadata) and configuration (environment files), preferably in separate repositories.
- Avoid functional changes: minor optimizations are fine but avoid making big functional changes while upgrading.
- Divide into sub-projects where possible: because of PDI/Kettle's lack of project support, projects often are bundled together. Identify separate sub-projects and upgrade them separately.
- Adopt Hop's life cycle management as soon as possible: use version control, unit testing, code reuse, logging, and monitoring to your advantage. The more transparency you create in your project, the better.
3. Upgrade in stages
Breaking the upgrading process for a large project into smaller chunks makes your entire upgrade process a lot more manageable.
Identify which parts of your project can be upgraded separately, what the dependencies are between those modules or sub-projects, and take them through the upgrade process one at a time.
Some of the advantages of upgrading your project into smaller parts:
- smaller sub-projects are easier to upgrade, manage and test
- upgrading smaller parts of your project reduces downtime for the overall project
- it is easier to identify reusable components in smaller parts.
- it is easier to identify dependencies between components
4. Enforce Code Freeze
With the projects and modules to upgrade in place, build an upgrade planning and timeline, and enforce a code freeze on each module while it is being upgraded.
Sometimes changes to a module that is being upgraded will be unavoidable, for example to backport a hotfix that needs to be applied to production. For these scenarios, it helps to create a procedure to apply these hotfixes to both the production environment (that is still PDI) and the Hop project that is being upgraded.
5. Apply best practices
Apache Hop is no different than any other software platform: a lot of the success of an Apache Hop project depends on the implementation.
Applying the Hop best practices puts you on a fast track to operational excellence.
Best practices cheat sheet
Apache Hop gives you a lot of freedom to implement projects the way you want. The Apache Hop best practices are advice based on real-life experiences and are intended to improve the overall quality of Hop projects.
- Naming conventions for pipelines, workflows, transforms, actions, and other metadata items. Once you have established a naming convention, don't forget to enforce it.
- Size matters: large workflows and pipelines are hard to debug and to maintain, and are potential performance bottlenecks.
- Variables should be defined in your project, with variable values in environment files. Keep code (workflows and pipelines) and configuration (environment files) completely separated.
- Re-use code with Metadata Injection, mappings, and code modules.
- Log everything about your workflow and pipeline execution
- Monitor performance: the slowest transform in a pipeline is a bottleneck. Check Hop Gui for slow transforms (dotted), use parallelism for CPU-heavy tasks.
- Loop in pipelines instead of workflows for optimal flexibility.
The best practices are available on the Apache Hop website. We'll cover these in more detail in later posts.
6. Test, test, test
With your Apache Hop and PDI/Kettle infrastructure set up in parallel, testing is quite straightforward.
Use Hop's integrated unit testing to its full potential to automate testing where possible.
Testing as a first-class citizen
Unit testing in Apache Hop is a fully integrated core functionality. Make testing a first-class citizen in your upgrade projects and beyond:
- automate the completeness and correctness testing between your PDI/Kettle and Hop systems
- test strategically: build unit tests for the core pipelines in your upgrade project, don't aim for a complete test library in your first sprint
- build regression tests for each bug you find and fix to ensure that all fixed bugs remain fixed.
- build environment checks to check infrastructure availability before your workflows run
- build a library of integration tests and run them on a regular basis (daily). Tests are only useful when executed frequently.
Revisit our Apache Hop unit testing guide to learn more.
7. Train and coach
Apache Hop is a large and quickly growing platform. A lot has changed since the project forked from PDI/Kettle, so upgrading your skills and knowledge is as important as upgrading the technology.
Bringing and keeping your and your team members' knowledge up to date is crucial for your project's success.
Apache Hop considers documentation a crucial part of the platform. The documentation on the Apache Hop website is available for all Hop versions since 1.0. The docs contain a lot of detailed information and a growing number of how-to guides.
Training, again, is only half of the work. A team culture where knowledge sharing and constantly coaching each other on best practices and new ways of working with Apache Hop, just like any other component in your data architecture, is crucial and will benefit the project and everyone involved.
The latest version of Apache Hop always is available for download at the Apache Hop download page.
What else can we cover?
Was this helpful to you? Let us know in the comments what other information you'd like to hear about upgrading to Apache Hop or about Apache Hop in general.
Feel free to reach out if you'd like to discuss the options to upgrade your Pentaho Data Integration project to Apache Hop.




Blog comments